
이번 절에서는 캐글에서 제공하는 타이타닉 탑승자 데이터를 기반으로 생존자 예측을 사이킷런으로 수행해본다.
타이타닉 탑승자 데이터에 대해 개략적으로 살펴보자
- passengerid: 탑승자 데이터 일련번호
- survived : 생존 여부, 0=사망, 1=생존
- pclass : 티켓의 선실 등급, 1=일등석, 2=이등석, 3=삼등석
- sex: 탑승자 성별
- name: 탑승자 이름
- Age : 탑승자 나이
- sibsp : 같이 탑승한 형제자매 또는 배우자 인원수
- parch: 같이 탑승한 부모님 또는 어린이 인원수
- ticket: 티켓번호
- fare: 요금
- cabin: 선실 요금
- embarked: 중간 정착 항구 C=Cherbourg, Q=Queenstown, S=Southampton
이번 예제에서는 시각화 패키지인 맷플롯립과 시본을 이용해 차트와 그래프도 함께 시각화한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
titanic_df = pd.read_csv('titanic_train.csv')
titanic_df.head(3)
로딩된 데이터 칼럼 타입을 DataFrame의 info() 메서드를 통해 알아보자
print('\n ### 학습 데이터 정보 ### \n')
print(titanic_df.info())
[output]
### 학습 데이터 정보 ###
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890 #891개의 로우
Data columns (total 12 columns): #칼럼 수 12개
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object #판다스의 object타입은 string 타입으로 봐도 무방
4 Sex 891 non-null object
5 Age 714 non-null float64 #177개의 null값
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object #608개의 null 값
11 Embarked 889 non-null object #2개의 null 값
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
사이킷런 머신러닝 알고리즘은 Null 값을 허용하지 않으므로 Null 값을 어떻게 처리할지 결정해야한다.
여기서는 DataFrame의 fillna()를 이용해 간단하게 Null 값을 평균 또는 고정값으로 변경한다.
Age의 경우는 평균 나이, 나머지 칼럼은 N 값으로 변경한다.
그다음 모든 칼럼의 Null 값이 없는지 다시 확인해본다.
titanic_df['Age'].fillna(titanic_df['Age'].mean(), inplace=True) #inplace=True--> 원본데이터도 결손데이터 처리
# fillna()를 이용해 반환 값을 다시 받지 않는다면 inplace=True 파라미터를 fillna()에 추가해야 실제 데이터 세트값도 변경됨
titanic_df['Cabin'].fillna('N',inplace=True)
titanic_df['Embarked'].fillna('N', inplace=True)
print('데이터 세트 Null 값 개수', titanic_df.isnull().sum().sum())
[output]
데이터 세트 Null 값 개수 0
남아있는 문자열 피처인 sex, cabin, embarked 의 값 분류를 먼저 살펴보자
print('Sex 값 분포:\n', titanic_df['Sex'].value_counts())
print('Cabin 값 분포:\n', titanic_df['Cabin'].value_counts())
print('Embarked 값 분포:\n', titanic_df['Embarked'].value_counts())
[output]
Sex 값 분포:
male 577
female 314
Name: Sex, dtype: int64
Cabin 값 분포:
N 687
G6 4
C23 C25 C27 4
B96 B98 4
E101 3
...
B69 1
C86 1
C118 1
E31 1
C49 1
Name: Cabin, Length: 148, dtype: int64
Embarked 값 분포:
S 644
C 168
Q 77
N 2
Name: Embarked, dtype: int64
Cabin(선실)의 경우, N이 687건으로 가장 많은 것도 특이하지만 속성값이 제대로 정리되지 않은 것을 확인할 수 있다.
C23 C25 C27과 같이 여러 Cabin이 한꺼번에 표기된 Cabin 값이 4건이나 된다.
Cabin의 경우 선실 번호 중 선실 등급을 나타내는 첫 번째 등급이 중요해보인다.
그 이유는 그 당시에는 빈부차별이 심했기 때문에 일등실에 투숙한 사람이 삼등실에 투숙한 사람보다 살아남을 확률이 높았을 것이다.
titanic_df['Cabin'] = titanic_df['Cabin'].str[:1]
print(titanic_df['Cabin'].head(3))
[output]
0 N
1 C
2 N
Name: Cabin, dtype: object
머신러닝 알고리즘을 적용해 예측을 수행하기 전에 데이터를 먼저 탐색해보자
첫 번째로 어떤 유형의 승객이 생존 확률이 높았는지 확인해보자
여성과 아이들, 노약자가 제일 먼저 구조 대상이고 부자나 유명인이 다음 구조 대상이었을 것이다.
삼등실에 탄 가난한 이들이 타이타닉 호와 운명을 함께 했을 것이다.
성별이 생존 확률에 어떤 영향을 미쳤는지, 성별에 따른 생존자 수를 비교해보자.
titanic_df.groupby(['Sex', 'Survived'])['Survived'].count()
[output]
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
Survived 칼럼은 레이블로서 결정 클래스값이다. survived 0=사망 1=생존
여자는 314명 중 233명으로 약 74,2%가 생존했지만, 남자의 경우에는 577명 중 109명만 살아남아 18.8%가 생존했다.
그래프로 확인해보기 위해 시본 패키지를 이용했다.
X축에 'Sex'칼럼, Y축에 'Survived' 칼럼 그리고 이들 데이터를 가져올 데이터로 DataFrame 객체명을 다음과 같이 입력하고, barplot()함수를 호출하면 가로 막대 차트를 쉽게 그릴 수 있다.
sns.barplot(x='Sex', y='Survived', data=titanic_df)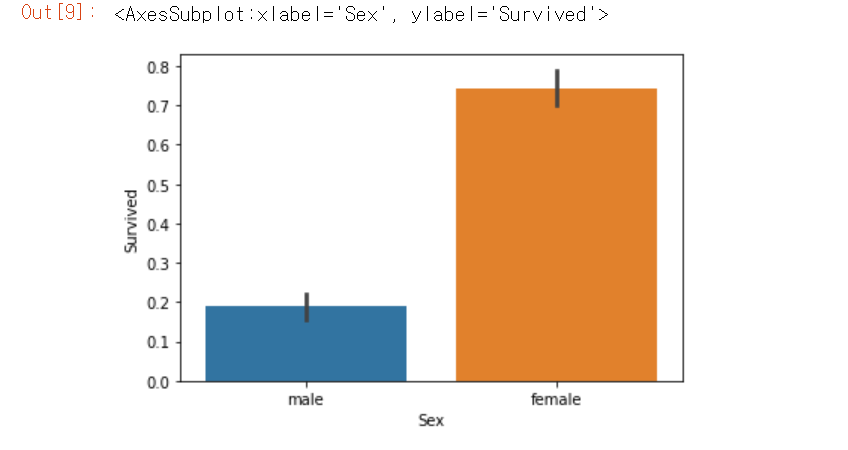
부자와 가난한 사람 간의 생존확률을 알아보기 위해 부를 측정할 수 있는 속성인 객실등급을 살펴보자
단순히 객실 등급별로 생존 확률을 보는 것보다는 성별을 함께 고려하여 분석하는 것이 더 효율적일 것 이다.
앞의 barchar()함수의 x좌표에 'Pclass'를 그리고 hue 파라미터를 추가해 hue ='Sex'와 같이 입력하면 간단하게 할 수 있다.
sns.barplot(x='Pclass', y='Survived', hue='Sex', data = titanic_df)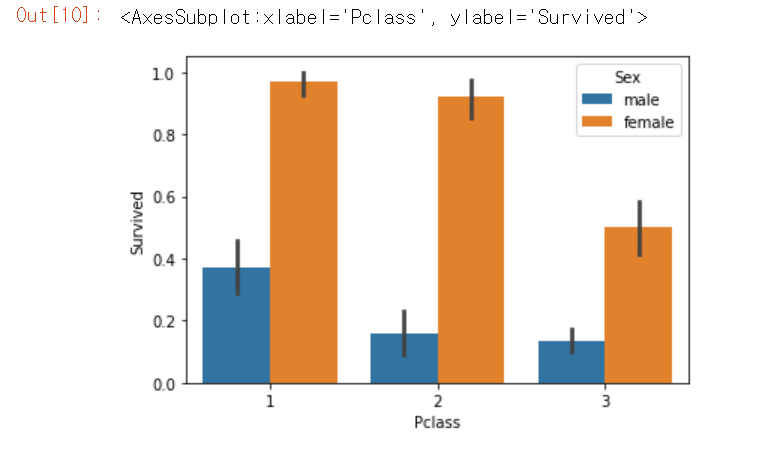
여성의 경우 일, 이등실에 따른 생존확률의 차이가 크지않으나 삼등실의 경우 생존 확률이 상대적으로 많이 떨어짐을 알 수 있다.
남성의 경우 일등실의 생존 확률이 이,삼등실보다 월등히 높다.
이번에는 Age에 따른 생존확률을 알아보자
0~5세 Baby, 6~12세 Child,13~18세 Teenager, 19~25 Student, 26~35세는 Young Adult, 36~60세는 Adul, 61세 이상은 Elderly로 분류한다.
-1 이하의 오류값은 Unknown으로 분류하였다.
여자 Baby의 경우 비교적 생존확률이 높지만 여자 Child의 경우에는 다른 연령대에 비해 생존확률이 나잤다.
그리고 여자 Elderly의 경우 생존확률이 매우 높았다.
이제 남아있는 문자열 카테고리 피처를 숫자형 카테고리 피처로 변환한다.
인코딩은 사이킷런 LabelEncoder 클래스를 이용해 레이블 인코딩을 적용한다.
LabelEncoder 객체는 카테고리 값의 유형 수에 따라 0~ (카테고리 유형수-1)까지 숫자값으로 변환한다.
사이킷런의 전처리 모듈의 대부분 인코딩 API는 fit(),transform()으로 데이터를 변환한다
여러 칼럼을 encode_features()함수를 새로 생성해 한 번에 변환해보자
from sklearn.preprocessing import LabelEncoder
def encode_features(dataDF):
features = ['Cabin', 'Sex', 'Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(dataDF[feature])
dataDF[feature] = le.transform(dataDF[feature])
return dataDF
titanic_df = encode_features(titanic_df)
titanic_df.head()
Sex, Cabin, Embarked 속성이 숫자형으로 바뀐 것을 알 수 있다.
지금까지 피처를 가공한 내역을 정리하고 이를 함수로 만들어 쉽게 재사용할 수 있도록 만들어보자
#Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Embarked'].fillna('N', inplace=True)
df['Fare'].fillna(0, inplace=True)
return df
#머신러닝 알고리즘에 불필요한 피처 제거
def drop_features(df):
df.drop(['PassnegerId', 'Name', 'Ticket'], axis=1, inplace=True)
return df
#레이블 인코딩 수행
def format_features(df):
df['Cabin']=df['Cabin'].str[:1]
features = ['Cabin', 'Sex', 'Embarked']
for features in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
#앞에서 설정한 데이터 전처리 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
데이터 전처리를 수행하는 transform_features() 함수를 만들었으니 이 함수를 이용해 다시 원본 데이터를 가공해보자
원본 CSV파일을 다시 로딩하고 타이타닉 생존자 데이터 세트의 레이블인 Survied 속성만 별도 분리해 클래스 결정값 데이터 세트로 만들어보자.
그리고 Survived 속성을 드롭해 피처 데이터 세트를 만든다.
이렇게 생성된 피처 데이터 세트에 transform_features()를 적용해 데이터를 가공한다.
#원본 데이터를 재로딩하고, 피처 데이터 세트와 레이블 데이터 세트 추출.
titanic_df = pd.read_csv('titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
내려받은 학습 데이터 세트를 기반으로 해서 train_test_split() API를 이용해 별도의 테스트 데이터 세트를 추출한다.
테스트 데이터 세트 크기는 전체의 20%로 한다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df,
test_size=0.2, random_state=11)
ML 알고리즘인 결정 트리, 랜덤 포레스트, 로지스틱 회귀를 이용해 타이타닉 생존자를 예측해보자
사이킷런 결정 트리를 위해서 DecisionTreeClassifier, 랜덤 포레스트를 위해 RandomForestClassifier, 로지스틱 회귀를 위해 LogisticRegression 클래스를 제공한다.
이들 사이킷런 클래스를 이용해 train_test_split()으로 분리한 학습 데이터와 테스트 데이터를 기반으로 머신러닝 모델을 학습(fit), 예측(predict)할 것이다.
예측 성능 평가는 정확도인 accuracy_score() API를 이용한다.
LogisticRegression의 생성인자로 입력된 solver = 'liblinear'는 로지스틱 회귀의 최적화 알고리즘을 liblinear로 설정하는 것이다.
일반적으로 작은 데이터 세트에서 이진 분류는 liblinear가 성능이 약간 더 좋은 경향이 있다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
#결정트리, Random Forest, 로지스틱 회귀를 위한 사이킷런 Classifier 클래스 생성
dt_clf = DecisionTreeClassifier(random_state=11)
rt_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression(solver='liblinear')
#Decision Tree Classifier 학습/예측/평가
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print('DecisionTreeClassifier 정확도:{0:.4f}'. format(accuracy_score(y_test, dt_pred)))
#RandomForestClassifier 학습/예측/평가
rt_clf.fit(X_train,y_train)
rt_pred = rt_clf.predict(X_test)
print('RandomForestClassifier 정확도:{0:.4f}'. format(accuracy_score(y_test, rt_pred)))
#LogisticRegresssion 학습/예측/평가
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
print('LogisticRegression 정확도:{0:.4f}'. format(accuracy_score(y_test, lr_pred)))
[output]
DecisionTreeClassifier 정확도:0.7877
RandomForestClassifier 정확도:0.8547
LogisticRegression 정확도:0.86593개 알고리즘 중 LogisticRegression이 타 알고리즘에 비해 높은 정확도를 나타내고 있다.
아직 최적화 작업을 수행하지 않았고, 데이터양도 충분하지 않기 때문에 어떤 알고리즘이 가장 성능이 좋다고 평가할 순 없다.
다음으론 교차검증으로 결정 트리 모델을 좀 더 평가해보자.
앞서 언급한 교차검증을 위한 사이킷런 model_selection 패키지의 KFold 클래스, cross_val_score(), GridSerchCV 클래스를 모두 사용한다.
먼저 사이킷런 KFold 클래스를 이용해 교차 검증을 수행하며, 폴드 개수는 5개로 설정한다.
from sklearn.model_selection import KFold
def exec_kfold(clf, folds=5):
#폴드 세트를 5개인 KFold 객체를 생성, 폴드 수만큼 예측 결과 저장을 위한 리스트 객체 생성
kfold = KFold(n_splits=folds)
scores=[]
#KFold 교차 검증 수행.
for iter_count, (train_index, test_index) in enumerate(kfold.split(X_titanic_df)):
#X_titani_df 데이터에서 교차 검증별로 학습과 검증 데이터를 가리키는 index 생성
X_train, X_test = X_titanic_df.values[train_index], X_titanic_df.values[test_index]
y_train, y_test = y_titanic_df.values[train_index], y_titanic_df.values[test_index]
#Classifier 학습, 예측, 정확도 계산
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
scores.append(accuracy)
print('교차 검증 {0} 정확도:{1:.4f}'.format(iter_count, accuracy))
#5개 fold에서의 평균 정확도 계산
mean_score = np.mean(scores)
print('평균 정확도: {0:.4f}'.format(mean_score))
#exec_kfold 호출
exec_kfold(dt_clf, folds=5)
[output]
교차 검증 0 정확도:0.7542
교차 검증 1 정확도:0.7809
교차 검증 2 정확도:0.7865
교차 검증 3 정확도:0.7697
교차 검증 4 정확도:0.8202
평균 정확도: 0.7823
평균 정확도는 약 78.23%이다. 이번에는 교차검증을 cross_val_score() API를 이용해 수행한다.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(dt_clf, X_titanic_df, y_titanic_df, cv=5)
for iter_count, accuracy in enumerate(scores):
print('교차 검증 {0} 정확도: {1:.4f}'.format(iter_count, accuracy))
print('평균 정확도: {0:.4f}'.format(np.mean(scores)))
[output]
교차 검증 0 정확도: 0.7430
교차 검증 1 정확도: 0.7753
교차 검증 2 정확도: 0.7921
교차 검증 3 정확도: 0.7865
교차 검증 4 정확도: 0.8427
평균 정확도: 0.7879
cross_val_score()과 KFold 평균정확도가 다른 이유는 cross_val_score()가 StratifiedKFold를 이용해 폴드세트를 분할하기 때문이다.
마지막으로 GridSerchCV를 이용해 DecisionClassifier 최적 하이퍼 파라미터를 찾고 예측성능을 측정해보자
CV는 5개의 폴드 세트를 지정하고 하이퍼 파라미터는 max_depth, min_samples_split, min_samples_leaf를 변경하면서 성능을 측정한다.
최적 하이퍼 파라미터와 그 때의 예측을 출력하고, 최적 하이퍼 파라미터로 학습된 Estimator 를 이용해 train_test_split()으로 분리된 테스트 데이터 세트에 예측 정확도를 출력해본다.
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':[2, 3, 5, 10],
'min_samples_split':[2, 3, 5], 'min_samples_leaf':[1, 5, 8]}
grid_dclf = GridSearchCV(dt_clf, param_grid=parameters, scoring='accuracy', cv=5)
grid_dclf.fit(X_train, y_train)
print('GridSearchCV 최적 하이퍼 파라미터:', grid_dclf.best_params_)
print('GridSearchCV 최고 정확도:{0:.4f}'.format(grid_dclf.best_score_))
best_dclf = grid_dclf.best_estimator_
#GridSearchCV의 최적 하이퍼파라미터로 학습된 Estimator로 예측 및 평가 수행
dpredictions = best_dclf.predict(X_test)
[output]
GridSearchCV 최적 하이퍼 파라미터: {'max_depth': 3, 'min_samples_leaf': 5, 'min_samples_split': 2}
GridSearchCV 최고 정확도:0.7992Ref) 파이썬 머신러닝 완벽가이드