
생활코딩 강의(데이터베이스- MySQL) 내용을 바탕으로 작성되었습니다.
1. 관계형데이터베이스의 필요성
- 중복된 데이터 = 개선할 필요성이 있다는 강력한 증거
- 중복된 데이터는 용량, 경제적, 수정의 어려움 등의 문제를 발생시킴
중복된 데이터 해결 방법
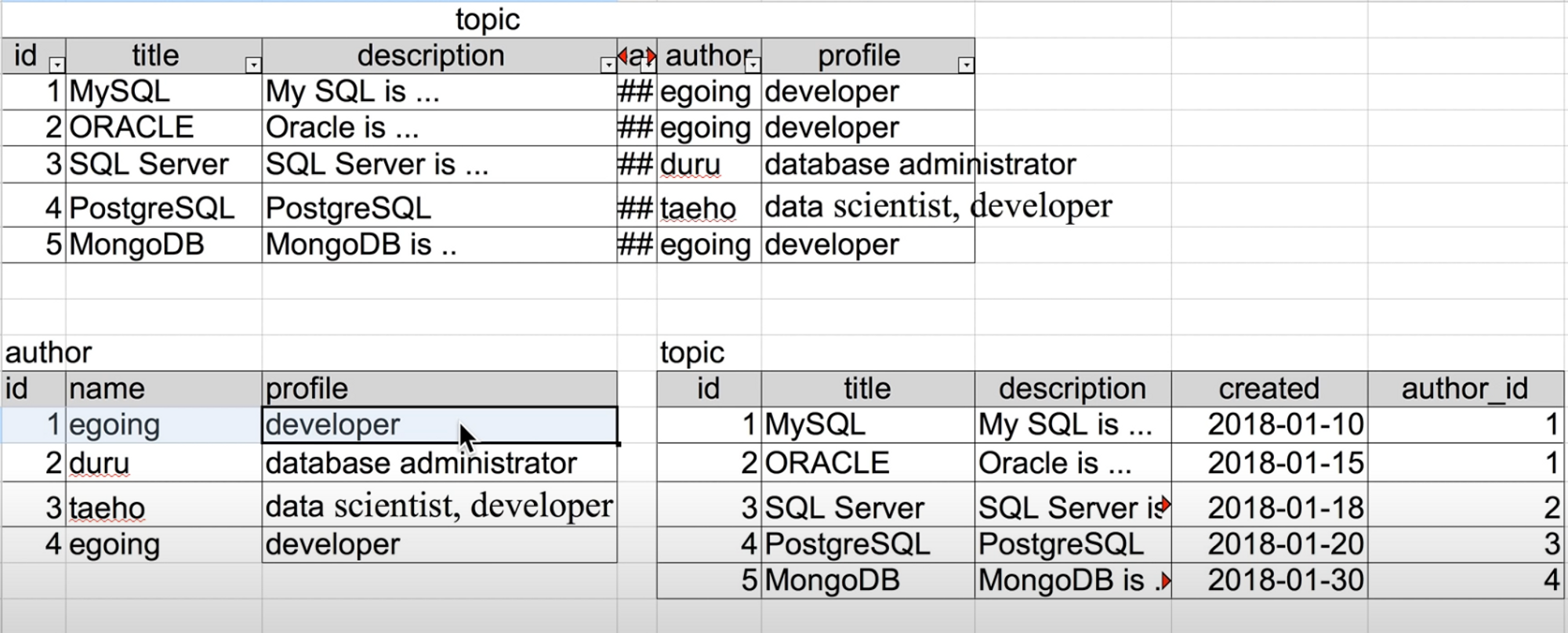
- 원본 topic 데이터에서 author, profile 칼럼의 egoing-developer 데이터가 1,2,5행에서 중복되고 있음
- author 테이블을 따로 만들고 topic 테이블에 author_id 칼럼을 부여하면 중복된 데이터가 사라짐
- author 테이블을 수정하게 되면 이 테이블을 참조하고 있는 모든 행에서 데이터가 수정될 수 있음
- id 1, 4와 같이 동명이인에 대해 다른 인덱스를 부여함으로써 구분 가능
- 데이터의 유지보수가 편해짐
- 표를 비교해 가면서 봐야 하는 불편함으로 tradeoff 현상 발생
- 데이터 저장은 분산해서, 볼 때는 한 번에 볼 수는 없을까? → MySQL에서는 가능!
2. 테이블 분리하기
- topic 테이블 이름을 topic_backup으로 변경
RENAME TABLE table_name TO table_name2;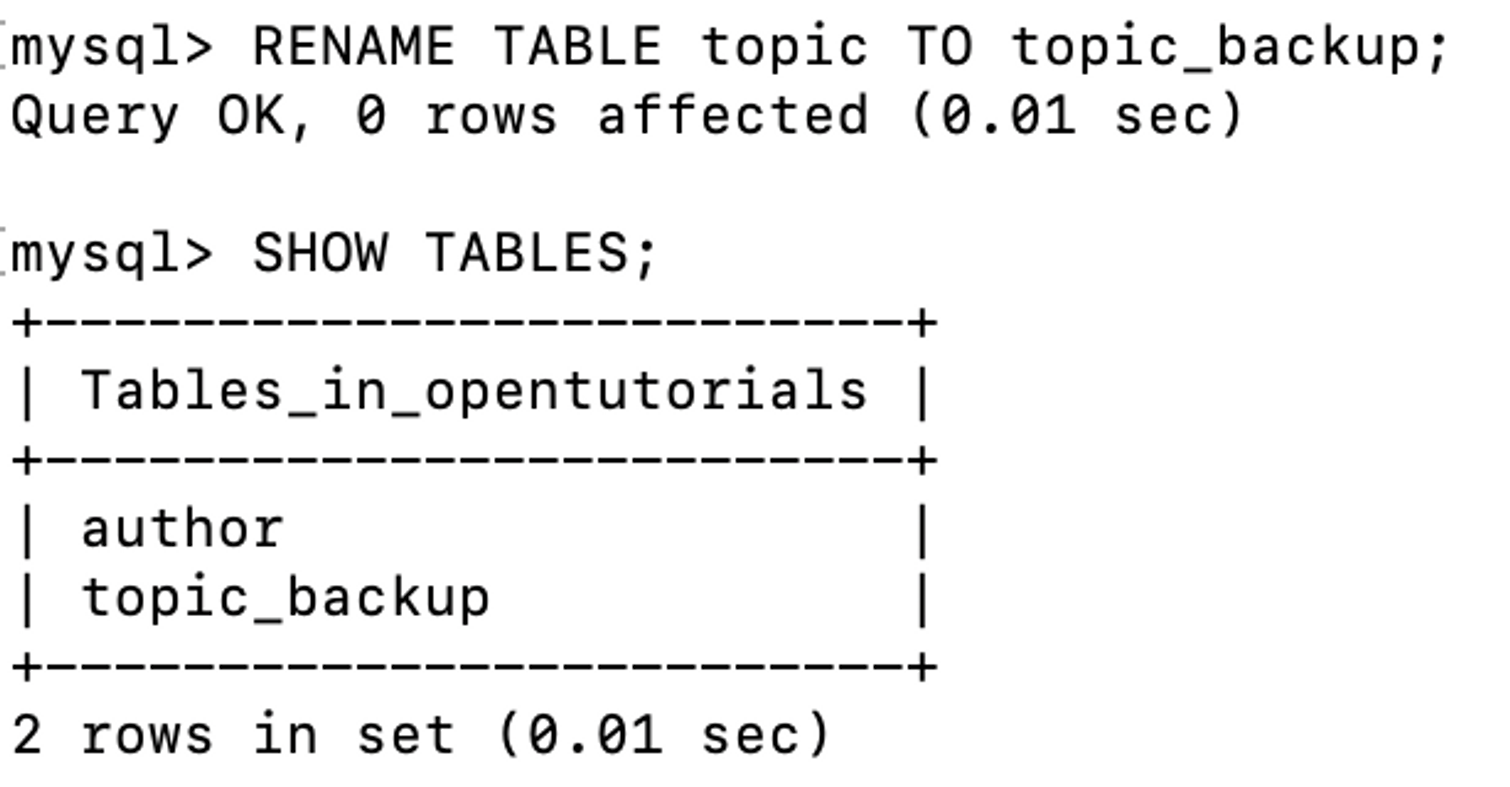
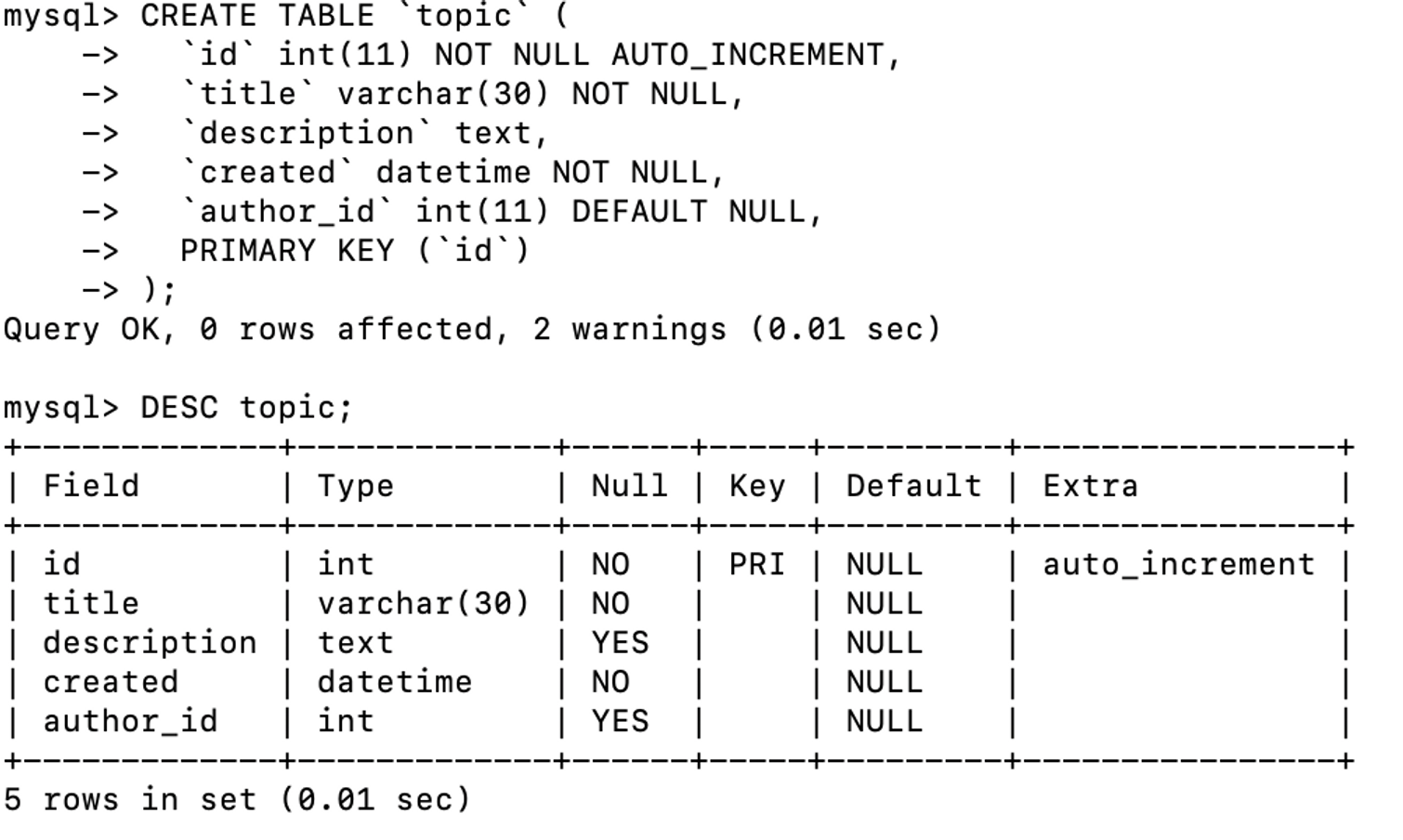
- topic_backup의 author 부분을 author_id로 바꿔서 topic 테이블을 만들어 author 테이블을 참조하도록 함
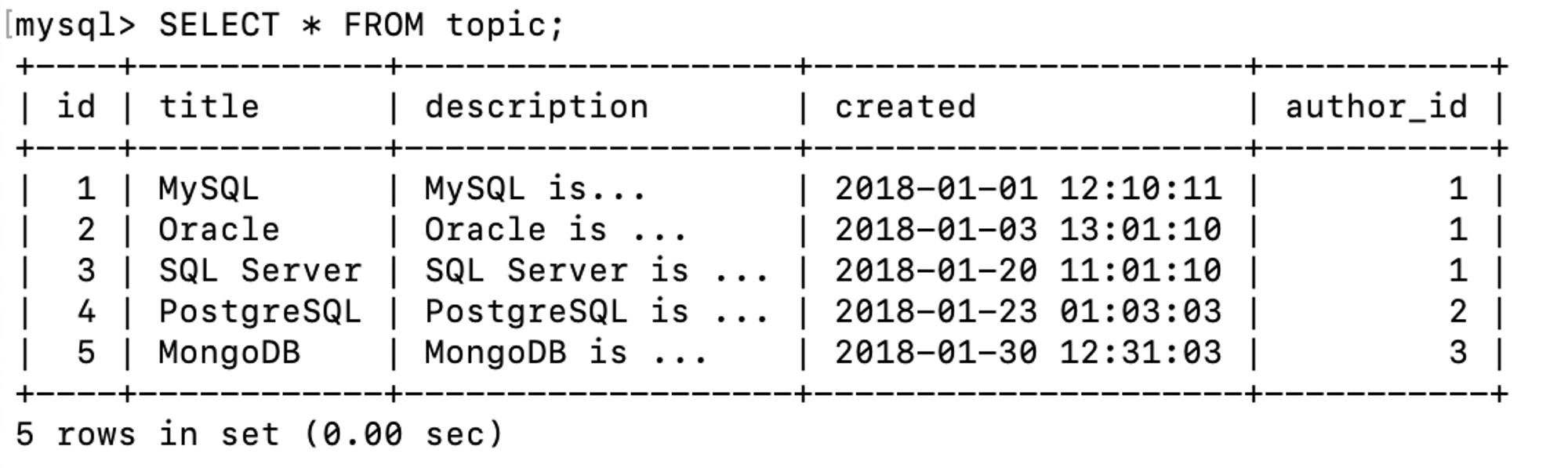
- topic 테이블 데이터값 입력
- author 테이블을 새로 만들고 데이터값 입력



3. JOIN
- 분리된 테이블을 읽을 때 하나의 테이블로 합쳐서 읽을 수 있게 함
- author, topic 테이블의 joint는 topic 테이블에서는 author_id값, author 테이블에선 id 값임
- MySQL에 author_id 값과 같은 author 테이블에 있는 행을 가져와서 topic 테이블에 결합하라고 명령을 내리면 됨
- join 된 표를 확인하면 author_id와 id의 같은 값끼리 같은 행에 둔 것을 확인할 수 있음

- SELECT 문으로 author_id, id 칼럼을 제외하고 데이터를 추출
- id 칼럼의 경우 topic, author 테이블에 모두 있어 ambigious(애매모호한) 하기 때문에 AS 문법을 통해 어떤 테이블의 id 칼럼인지 명시해 줌
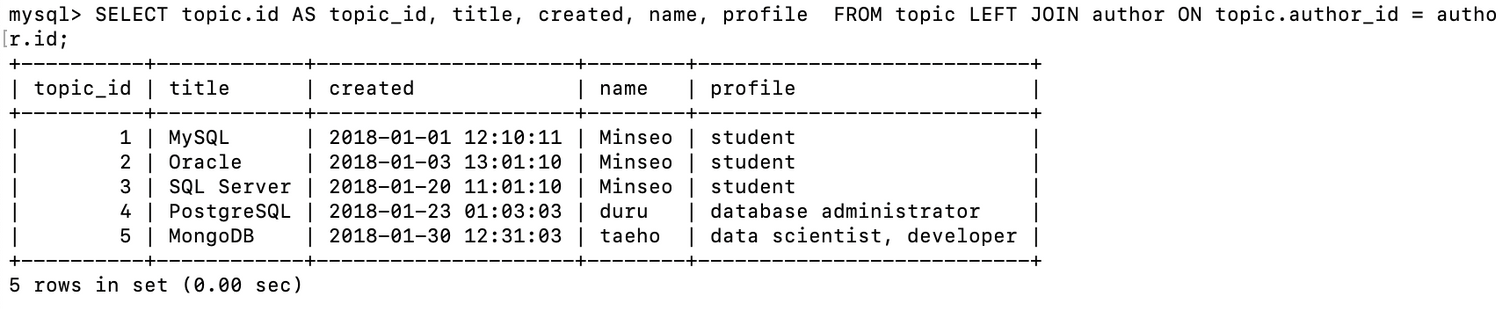
- 테이블을 분리한다는 것은 어떤 테이블이든지 author 테이블의 id와 일치하는 식별자 값을 그 행에 포함하고 있다면 join을 통해 관계를 맺고 데이터 값을 수정할 수 있음
'데이터 > 데이터베이스' 카테고리의 다른 글
| MySQL - CRUD (0) | 2023.02.11 |
|---|---|
| MySQL- 구조와 테이블 생성 (0) | 2023.02.11 |
| Database와 SQL (0) | 2023.01.21 |
생활코딩 강의(데이터베이스- MySQL) 내용을 바탕으로 작성되었습니다.
1. 관계형데이터베이스의 필요성
- 중복된 데이터 = 개선할 필요성이 있다는 강력한 증거
- 중복된 데이터는 용량, 경제적, 수정의 어려움 등의 문제를 발생시킴
중복된 데이터 해결 방법
- 원본 topic 데이터에서 author, profile 칼럼의 egoing-developer 데이터가 1,2,5행에서 중복되고 있음
- author 테이블을 따로 만들고 topic 테이블에 author_id 칼럼을 부여하면 중복된 데이터가 사라짐
- author 테이블을 수정하게 되면 이 테이블을 참조하고 있는 모든 행에서 데이터가 수정될 수 있음
- id 1, 4와 같이 동명이인에 대해 다른 인덱스를 부여함으로써 구분 가능
- 데이터의 유지보수가 편해짐
- 표를 비교해 가면서 봐야 하는 불편함으로 tradeoff 현상 발생
- 데이터 저장은 분산해서, 볼 때는 한 번에 볼 수는 없을까? → MySQL에서는 가능!
2. 테이블 분리하기
- topic 테이블 이름을 topic_backup으로 변경
RENAME TABLE table_name TO table_name2;
- topic_backup의 author 부분을 author_id로 바꿔서 topic 테이블을 만들어 author 테이블을 참조하도록 함
- topic 테이블 데이터값 입력
- author 테이블을 새로 만들고 데이터값 입력
3. JOIN
- 분리된 테이블을 읽을 때 하나의 테이블로 합쳐서 읽을 수 있게 함
- author, topic 테이블의 joint는 topic 테이블에서는 author_id값, author 테이블에선 id 값임
- MySQL에 author_id 값과 같은 author 테이블에 있는 행을 가져와서 topic 테이블에 결합하라고 명령을 내리면 됨
- join 된 표를 확인하면 author_id와 id의 같은 값끼리 같은 행에 둔 것을 확인할 수 있음
- SELECT 문으로 author_id, id 칼럼을 제외하고 데이터를 추출
- id 칼럼의 경우 topic, author 테이블에 모두 있어 ambigious(애매모호한) 하기 때문에 AS 문법을 통해 어떤 테이블의 id 칼럼인지 명시해 줌
- 테이블을 분리한다는 것은 어떤 테이블이든지 author 테이블의 id와 일치하는 식별자 값을 그 행에 포함하고 있다면 join을 통해 관계를 맺고 데이터 값을 수정할 수 있음
'데이터 > 데이터베이스' 카테고리의 다른 글
| MySQL - CRUD (0) | 2023.02.11 |
|---|---|
| MySQL- 구조와 테이블 생성 (0) | 2023.02.11 |
| Database와 SQL (0) | 2023.01.21 |