
목차
1. Apache airflow 개념
2. Airflow dask relationship branch 예제
3. Airflow ML 예제
I. Apache Airflow란?
workflow management tool로, 여기서 workflow란 ETL과 같은 작업의 흐름을 말한다.
즉, 이러한 workflow들을 작성, 스케줄링, 모니터링하면서 관리해주는 툴이다.
Airflow의 각 components 들의 아키텍처는 다음과 같다.
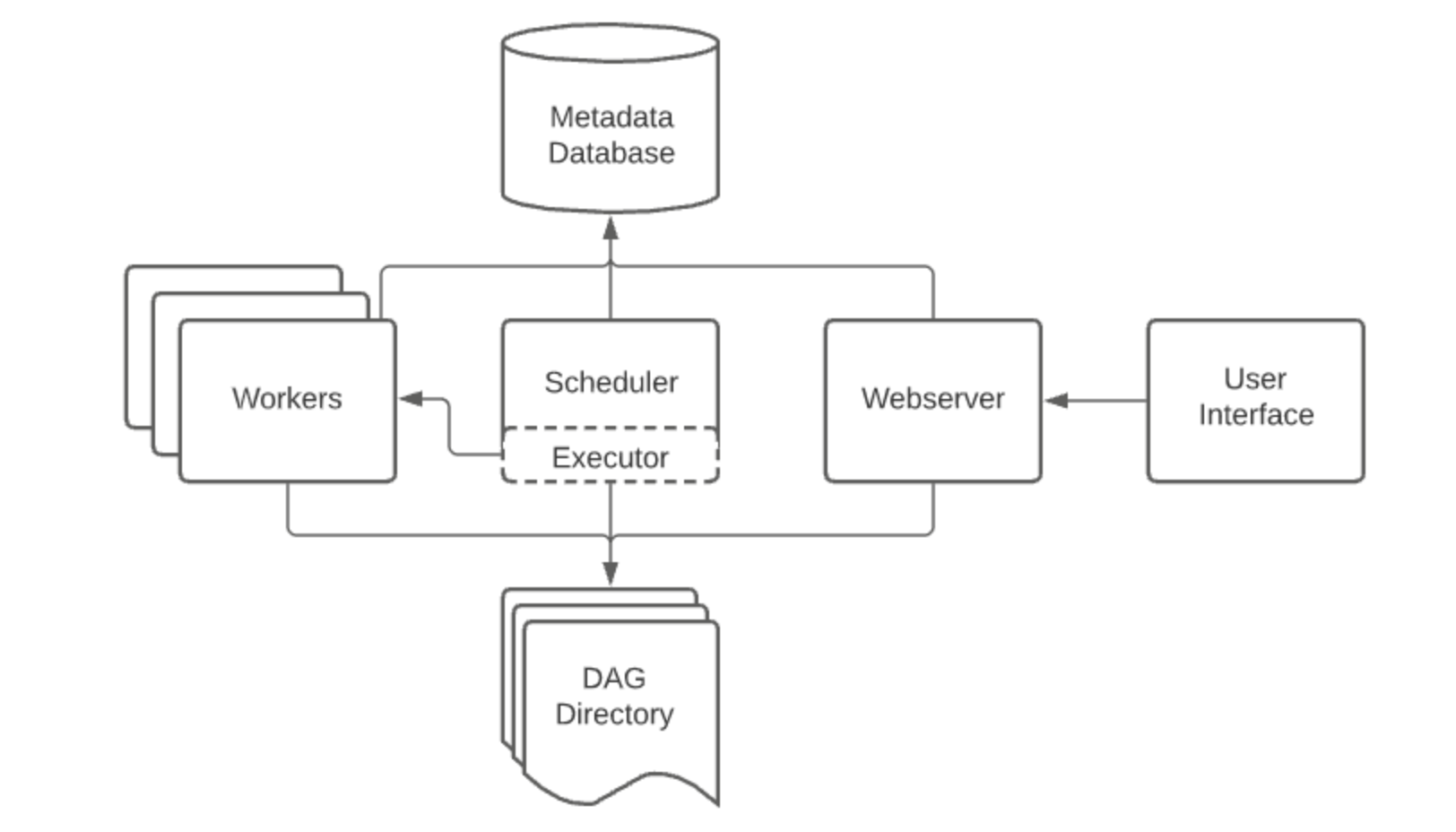
- Airflow Webserver
airflow 웹 서버는 UI를 통해 airflow의 로그를 보여주거나 스케줄러에 의해 생성된 DAG (Directed Acyclic Graph) 목록, Task상태를 시각화하여 보여준다.
- Airflow Scheduler
airflow 스케줄러는 airflow로 할당된 work들(=DAG)을 스케줄링 해주는 요소이다. 스케줄된 workflow들의 triggering과 실행하기 위해서 executor에게 task를 제공해주는 역할을한다.
- Airflow executor
airflow executor는 실행중인 task를 handling하는 component 이다.
defalult 설치시에는 scheduler 에 있는 모든 것들을 다 실행시키지만, production 수준에서의 executor는 worker에게 task를 push(요청)한다.
- Airflow worker
실제 task를 실행하는 주체자이다.
- Airflow database
airflow에 있는 DAG, Task등의 metadata를 저장하고 관리한다.
- DAG
DAG 는 싸이클이 없는 그래프로 노드와 노드가 단방향으로 연결되어있다. airflow는 DAG 를 이용하여 workflow를 구성하여 어떤 순서로 task를 실행시킬 것인지 dependency를 어떻게 표현할 것인지 설정한다.
Airflow 설치 및 기본셋팅, 실행
1. 경로 및 환경 변수 설정
airflow는 user path에 설치할 것을 권장하고 있기에 해당 경로에 설치하도록 한다.
가상환경을 세팅하고 이 환경 내에서 airflow를 설치한다.
#가상환경생성
python3 -m venv ~/{directory_name}/{myenv}
# airflow를 실행시킬 디렉토리 설정
export airflow=~/{directory_name}/airflow
#가상환경 활성화
source {myenv}/bin/activate
airflow 설치 경로 : /Users/<user_name>/airflow
python 버전 : 3.9.12
airflow 버전 : 2.2.3
이제 airflow 를 설치해본다.
pip install "apache-airflow[celery]==2.3.0" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.3.0/constraints-3.7.txt"
2. Airflow 실행 전 셋팅
airflow를 실행시키기 전, 가장 먼저 DB 초기화가 필요하다.
DB는 Airflow의 DAG와 Task등을 관리하기 때문에 셋팅이 필요하다.
airflow db init
airflow가 설치된 경로에 구성된 디렉토리를 살펴보자
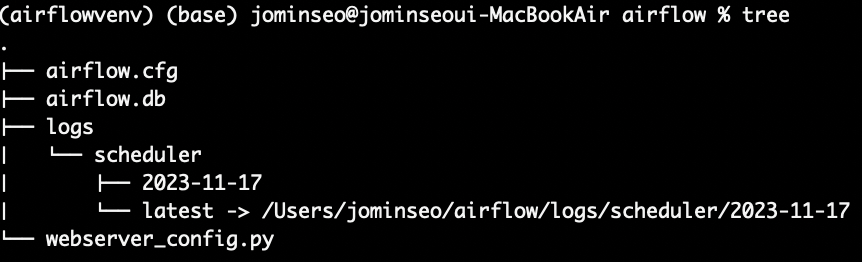
- airflow.cfg : airflow의 환경설정 파일
- airflow.db : db관련된 정보를 담고 있는 파일
- logs : airflow의 각종 로그들을 관리
- dags : airflow에서 dag를 관리하는 디렉토리 << airflow.cfg 파일안에 설정되어있다고 한다!
이제 airflow를 관리할 사용자 계정을 만든다.
airflow users create \
> --username <username> \
> --firstname <firstname> \
> --lastname <lastname> \
> --role <Admin> \
> --email <email>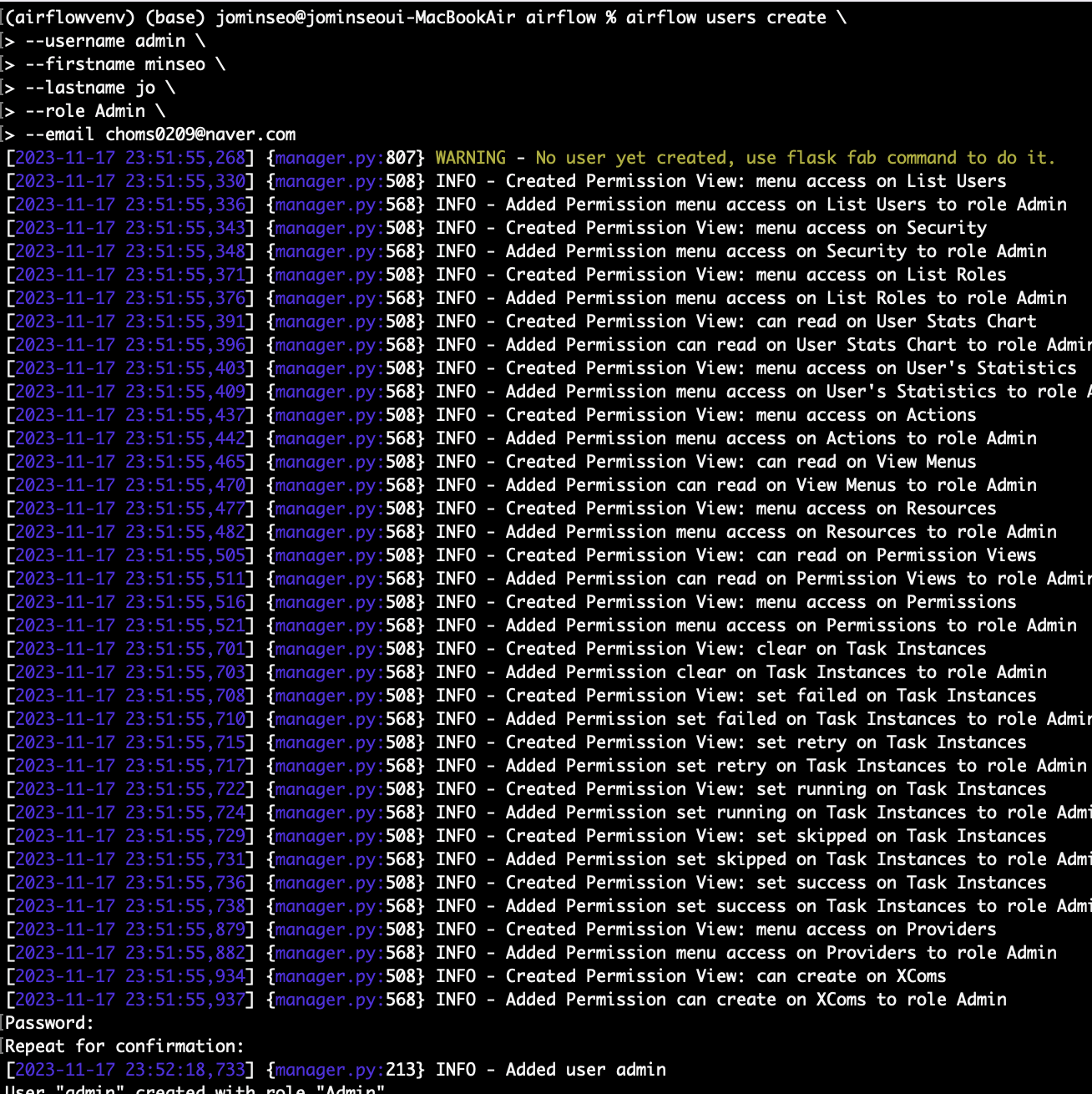
마지막으로 비밀번호 설정도 해주면 된다.
3. Airflow webserver 실행
airflow webserver --port 8080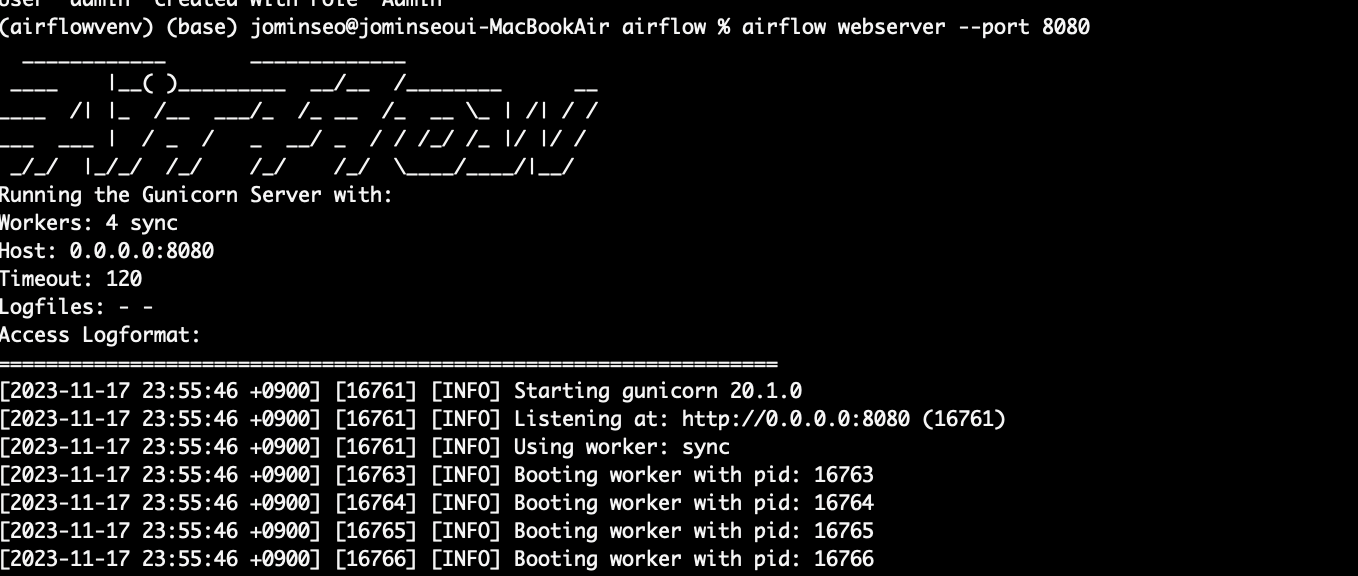
8080포트를 타고 들어가면 로그인 후 다음과 같은 airflow ui를 확인할 수 있다.
이 부분이 앞서 언급했던 airflow webserver이다.
3. airflow 예제 살펴보기
airflow는 DAG 를 관리하는 디렉토리를 지정해 관리한다. 그 디렉토리는 airflow.cfg파일 안에 설정되어있다.

해당 경로에 있는 dag 정보를 이용해서 airflow는 dags 를 표시하고 관리한다.
따라서 dag 디렉토리에 들어가서 dag 정보를 저장할 python 파일을 만들어준다. (airflow는 python기반이니까!)
vi example_dags.py
https://airflow.apache.org/docs/apache-airflow/stable/_modules/airflow/example_dags/tutorial.html
airflow.example_dags.tutorial — Airflow Documentation
airflow.apache.org
해당 문서에서 예제코드 파일을 확인할 수 있다.
"""
### Tutorial Documentation
Documentation that goes along with the Airflow tutorial located
[here](https://airflow.apache.org/tutorial.html)
"""
from __future__ import annotations
# [START tutorial]
# [START import_module]
from datetime import datetime, timedelta
from textwrap import dedent
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.bash import BashOperator
# [END import_module]
# [START instantiate_dag]
with DAG(
"tutorial",
# [START default_args]
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
default_args={
"depends_on_past": False,
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
# 'wait_for_downstream': False,
# 'sla': timedelta(hours=2),
# 'execution_timeout': timedelta(seconds=300),
# 'on_failure_callback': some_function, # or list of functions
# 'on_success_callback': some_other_function, # or list of functions
# 'on_retry_callback': another_function, # or list of functions
# 'sla_miss_callback': yet_another_function, # or list of functions
# 'trigger_rule': 'all_success'
},
# [END default_args]
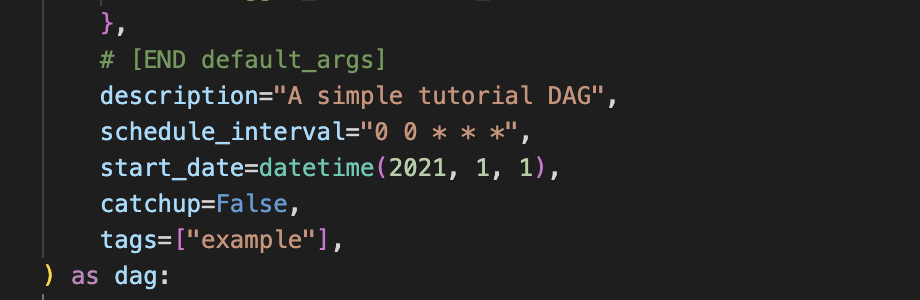
description="A simple tutorial DAG",
schedule_interval="0 0 * * *",
start_date=datetime(2021, 1, 1),
catchup=False,
tags=["example"],
) as dag:
# [END instantiate_dag]
# t1, t2 and t3 are examples of tasks created by instantiating operators
# [START basic_task]
t1 = BashOperator(
task_id="print_date",
bash_command="date",
)
t2 = BashOperator(
task_id="sleep",
depends_on_past=False,
bash_command="sleep 5",
retries=3,
)
# [END basic_task]
# [START documentation]
t1.doc_md = dedent(
"""\
#### Task Documentation
You can document your task using the attributes `doc_md` (markdown),
`doc` (plain text), `doc_rst`, `doc_json`, `doc_yaml` which gets
rendered in the UI's Task Instance Details page.

**Image Credit:** Randall Munroe, [XKCD](https://xkcd.com/license.html)
"""
)
dag.doc_md = __doc__ # providing that you have a docstring at the beginning of the DAG; OR
dag.doc_md = """
This is a documentation placed anywhere
""" # otherwise, type it like this
# [END documentation]
# [START jinja_template]
templated_command = dedent(
"""
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
{% endfor %}
"""
)
t3 = BashOperator(
task_id="templated",
depends_on_past=False,
bash_command=templated_command,
)
# [END jinja_template]
t1 >> [t2, t3]
# [END tutorial]
해당 코드를 살펴보면 t1, t2, t3를 airflowoperator로 정의하고 있다.
- Airflow Operator란?
- airflow는 operator를 통해 task를 정의한다.
- 위의 코드와 같이 bashoperator, python operator, dummy operator 등 다양한 operator종류가 있다.
- 각 operator는 수행하는 주체와 목적이 다르다!
- Task Relationship
- 각 task 는 ">>" ,"<<" , "[]"을 이용하여 dag 그래프를 그릴 수 있다. ex) t1 >> [t2, t3]
- first_task.set_downstream(second_task), third_task.set_upstream(second_task) 와 같은 형태로도 가능하다
1. args 설정 및 DAG객체 생성
- default_args
- DAG를 구성할 때 필요한 default argument를 셋팅하는 인자이다.
- DAG 객체 생성
- DAG 이름, schedule interval등을 셋팅한다.
- 실제 dag를 수행하는 작업(task)을 명시한다.
- operator, task 연결은 이 객체 안에서 수행된다.
dags webserver로 다시 들어가보면 방금 작성한 "Tutorial" dag 객체를 확인할 수 있다.
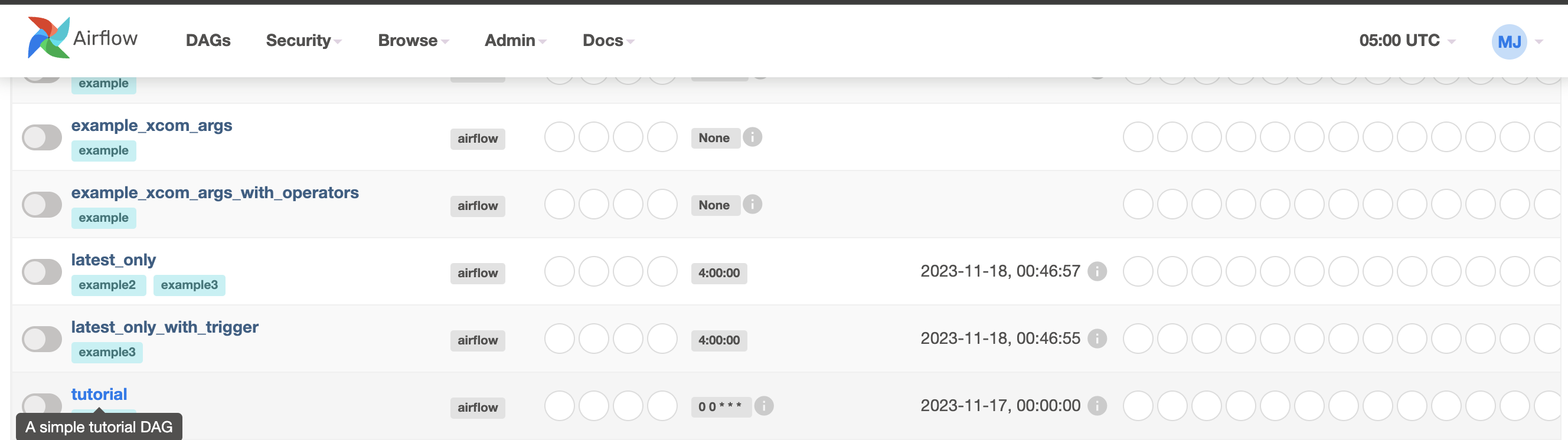
작성했던 dag 그래프도 정상적으로 확인된다!
2. airflow scheduler 실행
DAG 를 구성한 후 airflow scheduler를 실행시켜준다.
스케줄러는 DAG 에 있는 workflow 작업들을 스케줄링 하는 역할을 하기 때문에 이를 실행시켜줘야 관리가 가능하다.
airflow scheduler
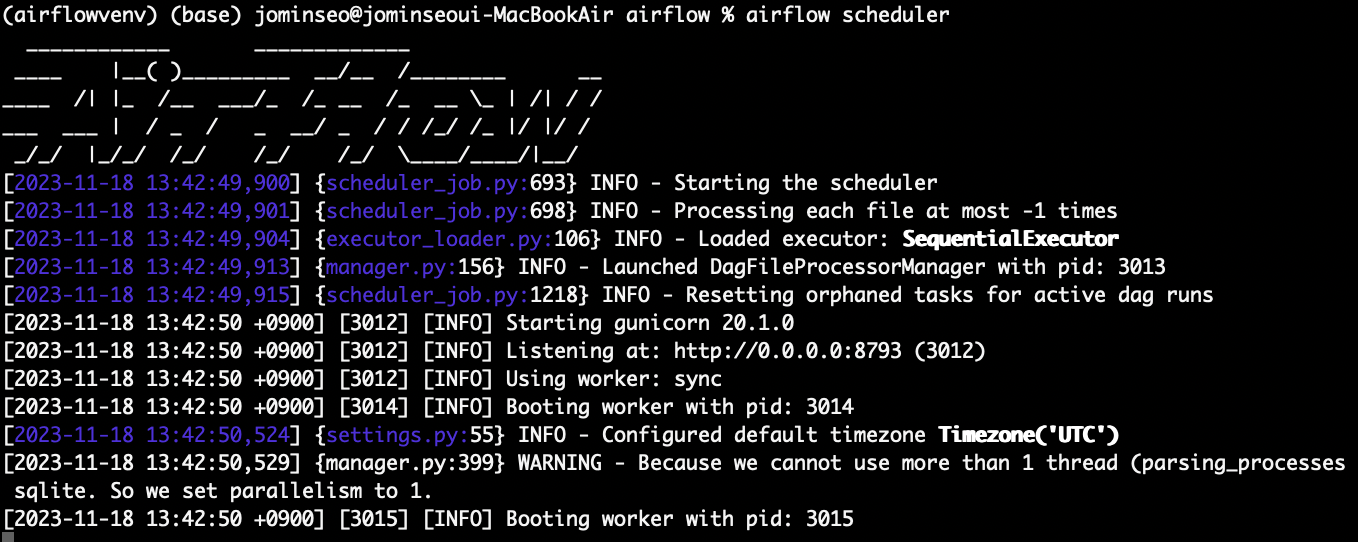
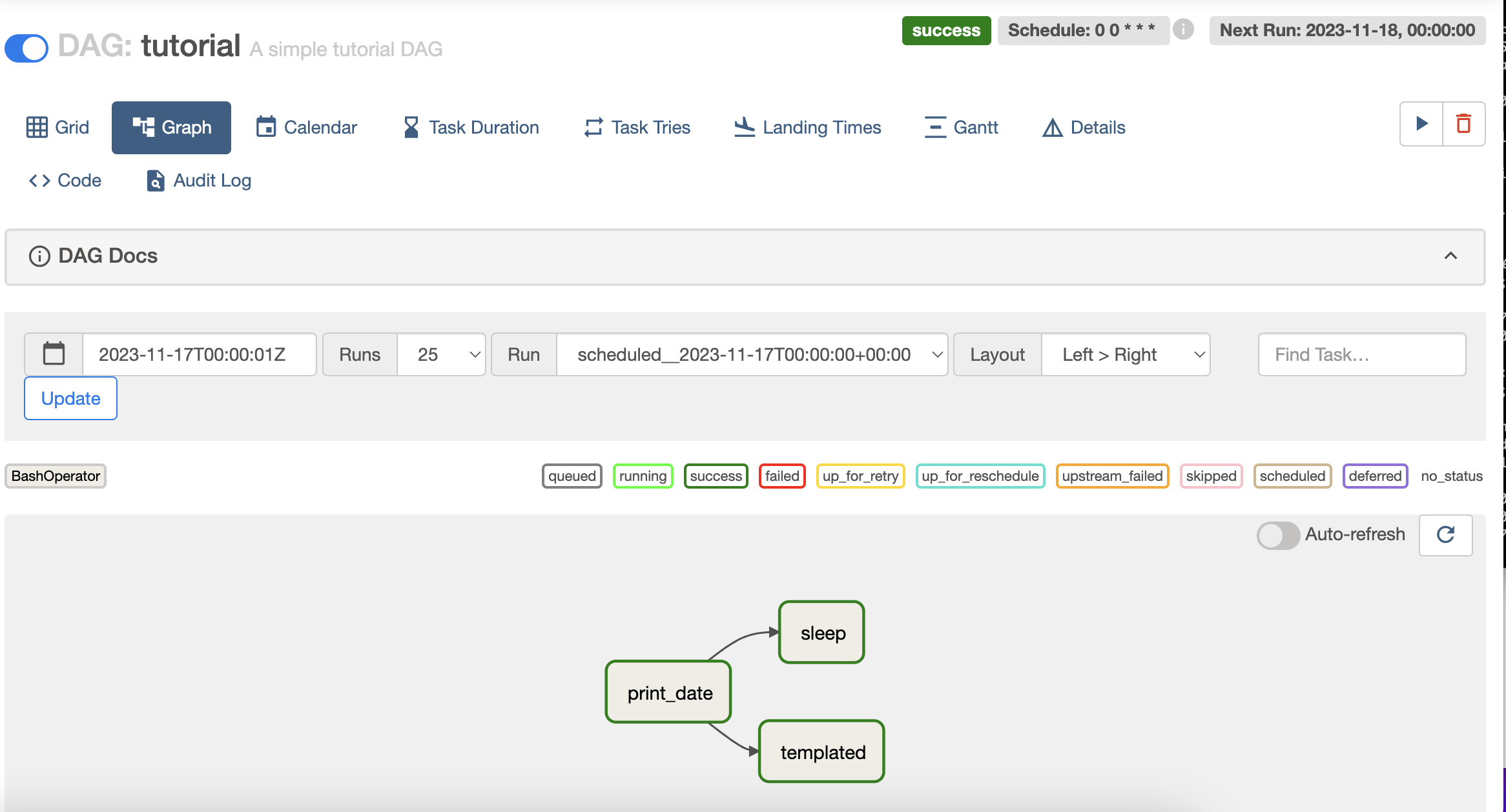
task들이 running 되고 있는 것을 확인할 수 있다.
dag 객체를 선언할 때 cron표현식으로 "0 0 * * *"으로 설정해주었기 때문에 이 DAG 는 매일 자정에 실행된다는 것을 의미한다.
DAG 의 작업 실행 및 로그에 대한 정보를 살펴보자
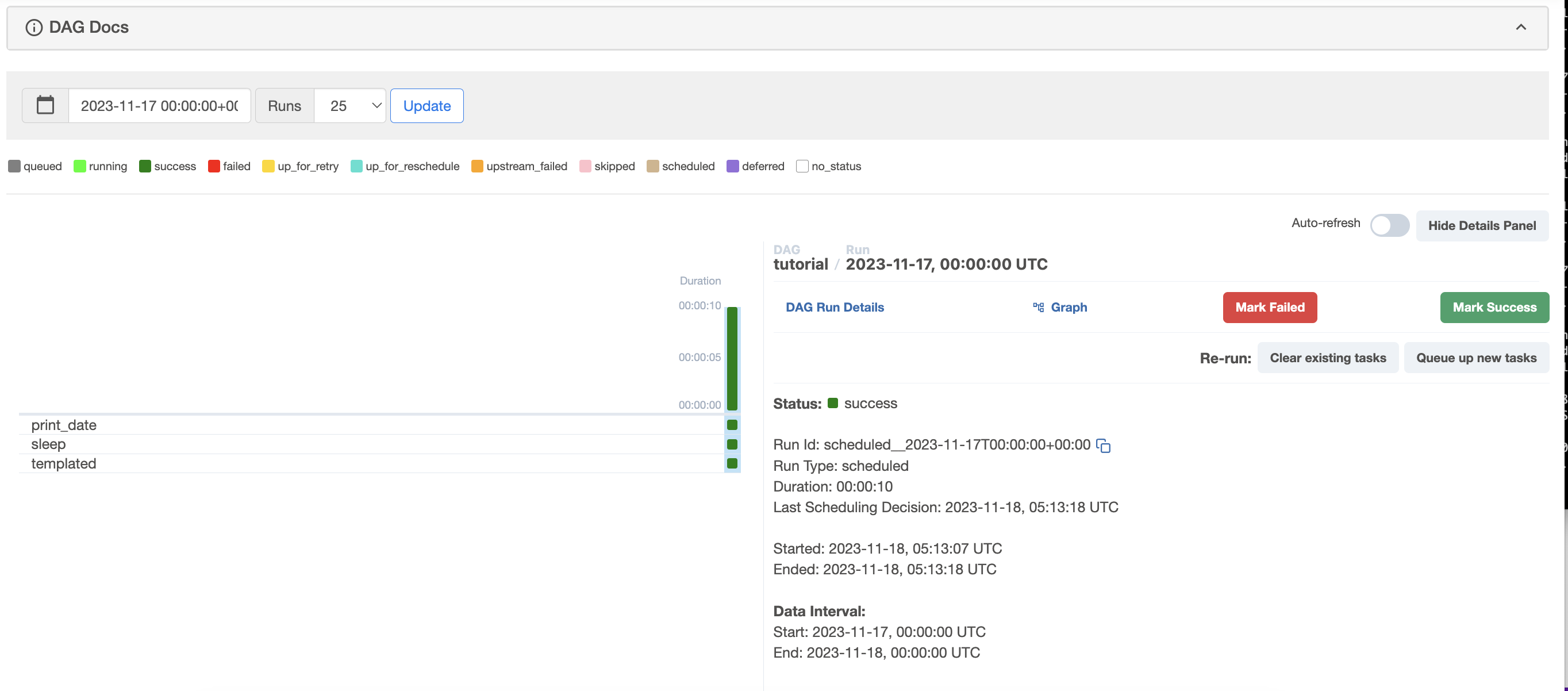
- Status : sucess
- 현재 DAG의 task 실행 상태가 성공했다는 것을 확인할 수 있다.
- Run Id: scheduled__2023-11-17T00:00:00+00:00
- task실행의 고유 식별자로 설정한 스케줄에 따라 실행된 작업임을 나타낸다.
- Run Type: scheduled
- task가 예약된 스케줄에 따라 실행된 것을 의미한다.
- Duration: 00:00:10
- task실행에 소요된 시간으로 10초가 걸린 것을 의미한다.
- Last Scheduling Decision: 2023-11-18, 05:13:18 UTC
- 마지막으로 언제 스케줄링이 됐는지 나타내준다.
- Started: 2023-11-18, 05:13:07 UTC, Ended: 2023-11-18, 05:13:18 UTC
- 작업이 실행되고 종료된 시간이다.
- Data Interval:
- 작업에서 처리한 데이터의 시간 간격을 나타낸다. 매일 자정에 스케줄링이 되기때문에 매일 자정마다 시작과 종료가 이루어지는 것을 확인할 수 있다.
각 task에 대한 로그 정보도 확인할 수 있다.
로그를 통해 작업이 어떻게 수행되었는지, 실행된 명령어와 결과는 무엇인지 확인할 수 있다.
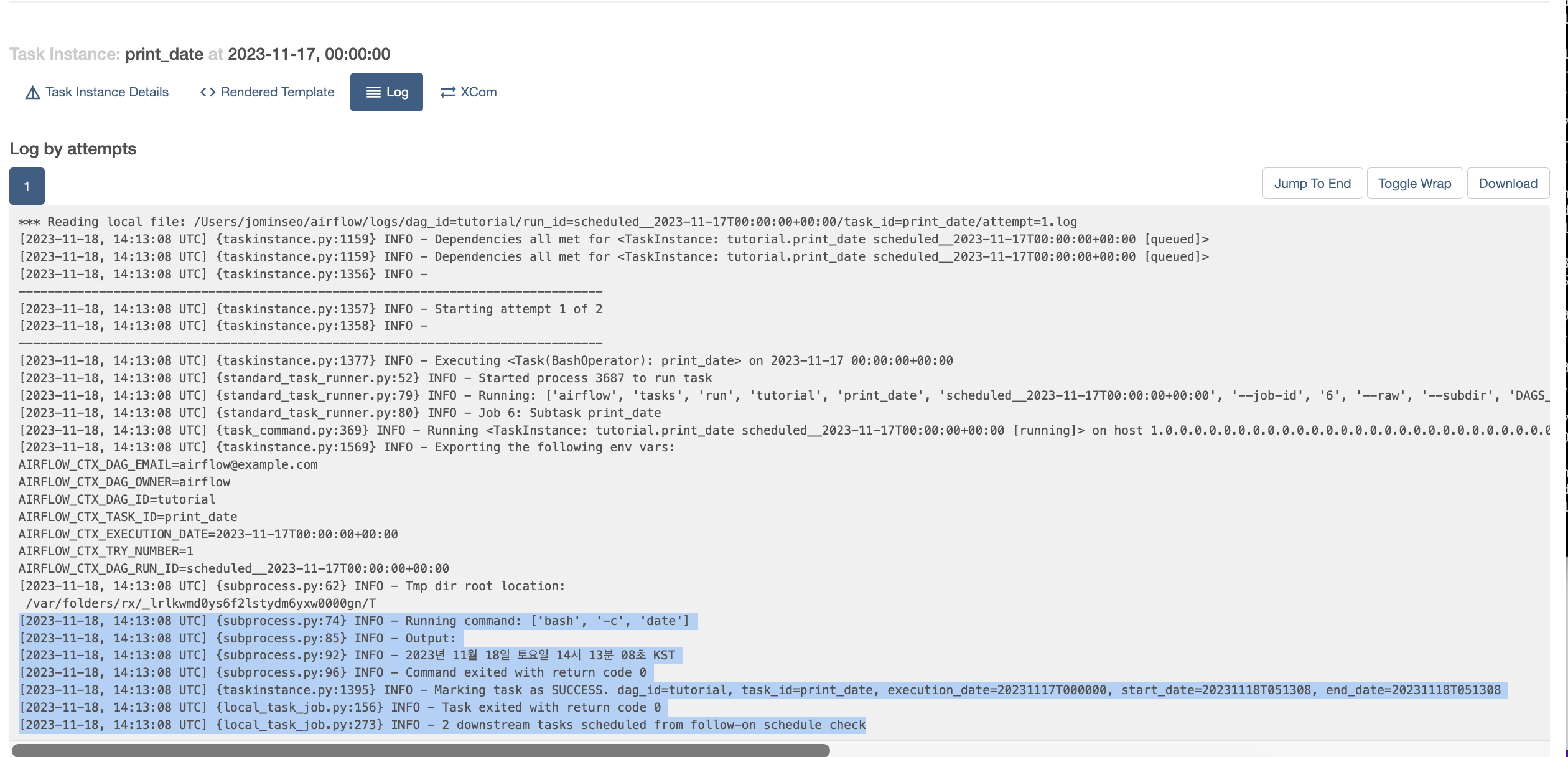
print_date 작업의 경우 'date'라는 command 명령어를 수행하였으며, 이에 따른 output은 "2023년 11월 18일 토요일 14시 13분 08초 KST" 이다.
작업이 성공적으로 마무리 되었다는 0 표시를 확인할 수 있고 "2 downstream tasks scheduled from follow-on schedule check"
현재 작업 이후에 2개의 하위 작업이 남아있다는 것을 확인할 수 있다.
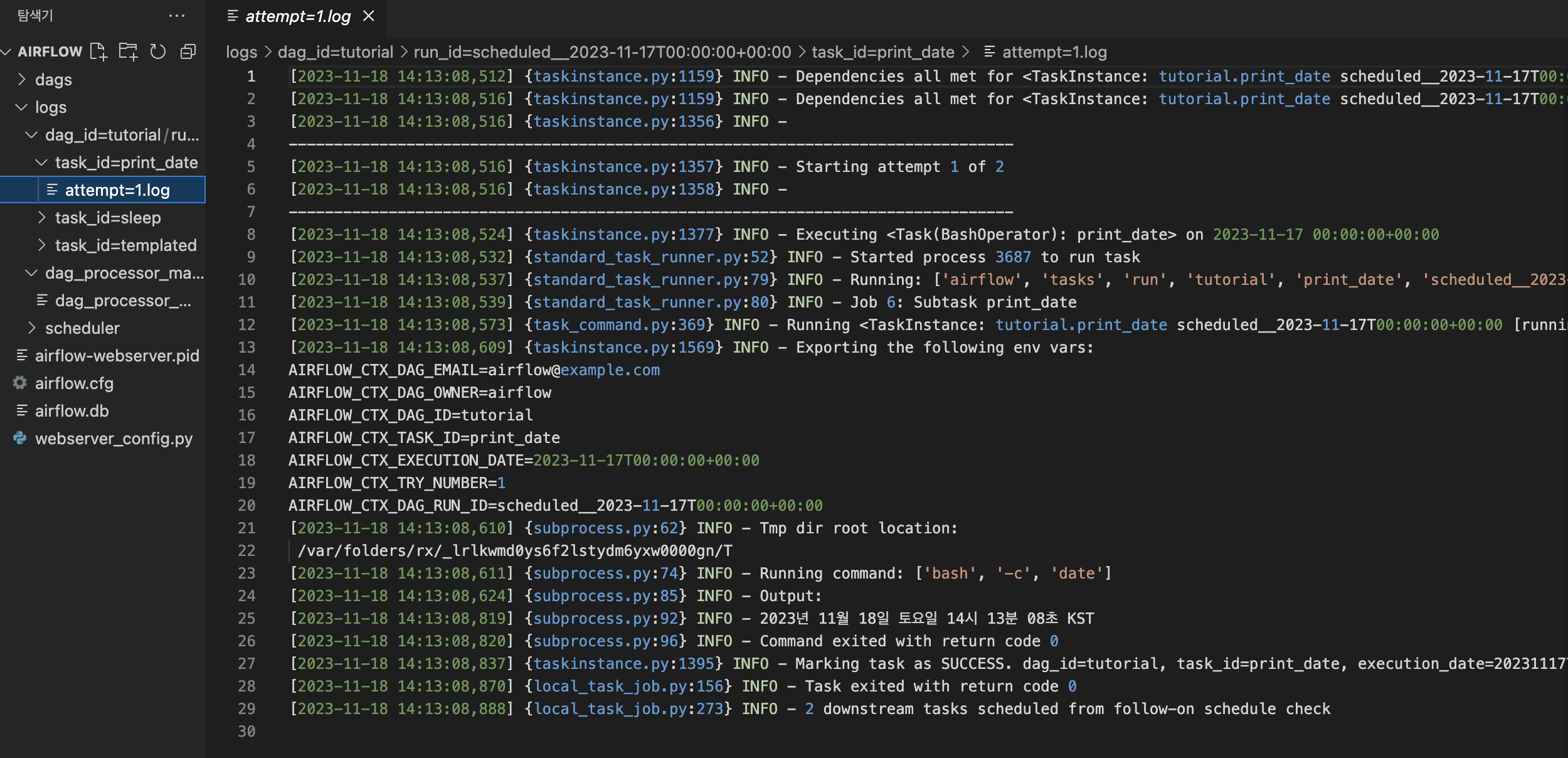
해당 로그는 airflow 경로에 있던 logs 디렉토리에서도 확인할 수 있다.
Airflow command 명령어
airflow에는 dag와 task를 관리하는 다양한 명령어가 존재한다. 자주 쓰이는 명령어를 알아보자.
airflow 에는 어떤 dag가 있고 해당 dag에 어떤 작업들이 있는지 확인하는 명령어이다.
# 에어플로우에 어떤 dags들이 존재하는지
airflow dags list
# 해당 dag id 에 어떤 task들이 존재하는지
airflow tasks list {dag id}
#task들을 tree 형태로 확인
airflow tasks list {dag id} --tree
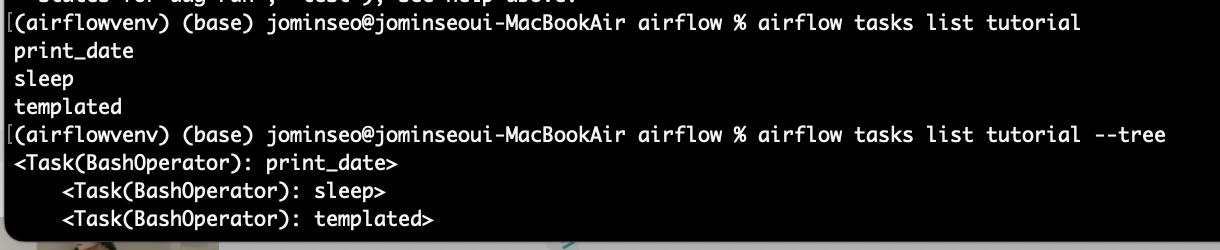
다음 command line으로 dags 를 test 해볼 수도 있다.
airflow dags test {dag_id}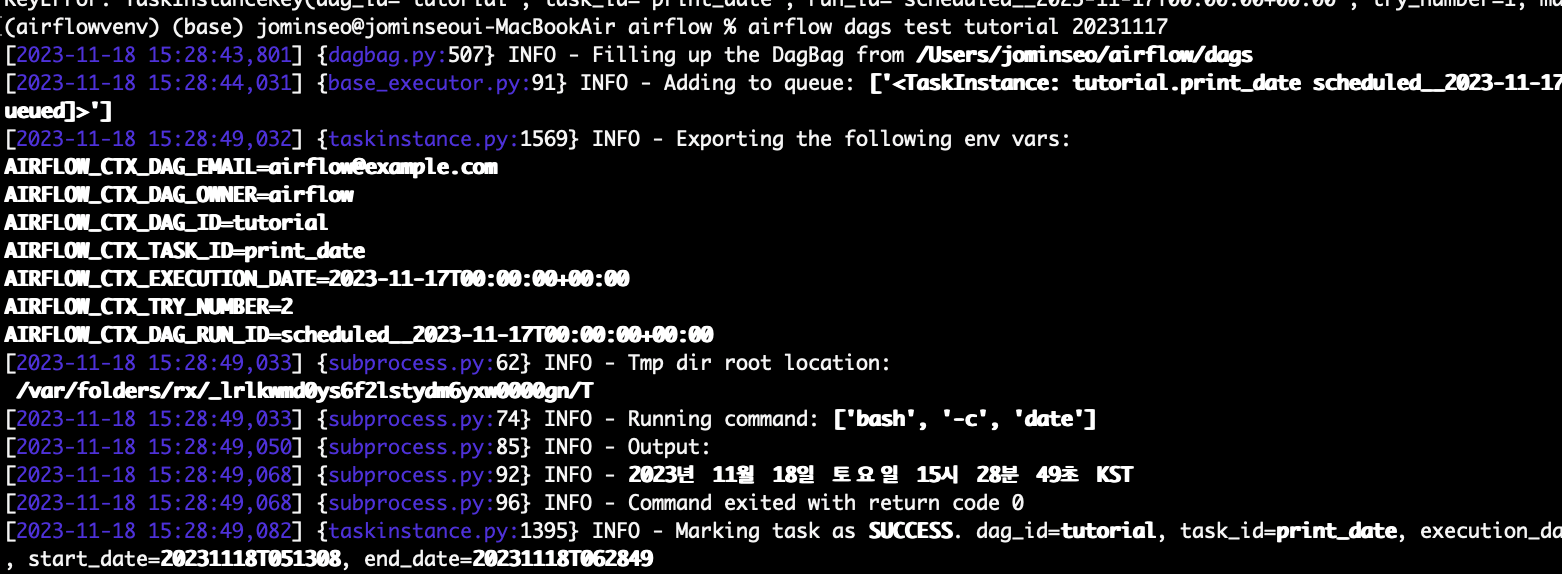
II. Airflow dask relationship branch 예제 및 python operator 활용하기
이제 airflow 예제 중 branch(분기) 하는 방법과 python operator를 활용하는 예제, airflow xcom이 무엇인지 살펴보자
dag 의 workflow는 비순환 구조라는 것과 또 다른 특징 중 하나는 branch이다.
branch는 다양한 경로 중 어떤 조건에 따라 특정 경로로 이동하게 하며, 나머지 경로로는 가지 않도록 하는 분기점을 두게하는 역할을 한다.
이는 airflow operator 중 branch operator를 활용하여 정할 수 있다.
BranchPythonOperator를 활용하여 실습을 진행해보자
코드를 직접 쳐보면서 각 operator와 파라미터의 역할에 대해 공부해보는게 좋을 것 같다!
1. 필요 라이브러리 import
airflow에서 python을 활용해 branch를 사용하려면 airflow.operator.python 모듈에 있는 BranchPythonOperator를 import 해야한다. 그 외의 operaotr도 import해주어서 각 task를 구성하고 task끼리의 순서를 정해주면 된다.
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import BranchPythonOperator
from airflow.utils.trigger_rule import TriggerRule
2. dag_args 설정
DAG 객체를 만들어주기 위한 argument 설정을 딕셔너리 형태로 해주었다.
이렇게 딕셔너리로 입력해두고 객체를 만들 때 **dags_args로 파라미터를 전달해주면 해당 설정에 맞게 DAG 가 생성된다.
dag_args = {
"dag_id" : "BranchOperator",
"default_args" : {
"owner" : "minseo",
"start_date" : datetime(2023, 1, 1),
"retries" : 1, # 작업이 실패할 경우 재시도횟수
"retry_delay" : timedelta(minutes=5) #작업을 재시도할 떄 까지의 대기시간 5분으로 설정
},
"description" : "Minseo's example DAG",
"schedule_interval" : timedelta(days=1) #스케줄 주기는 1일
}
def random_branch_path():
from random import radint
return "path1" if radint(1,2) == 1 else "my_name_en"
3. DAG 객체의 task 정의
with DAG( **dag_args ) as dag:
t1 = BashOperator(
task_id = 'print_date',
bash_command = 'date',
)
t2 = BranchPythonOperator(
task_id = 'branch',
python_callable = random_branch_path,
)
t3 = BashOperator(
task_id = 'my_name_ko'
depends_on_past = False,
bash_command = 'echo "안녕하세요".',
)
t4 = BashOperator(
task_id = 'my_name_en',
depends_on_past = False
bash_command = 'echo "Hi"',
)
complete = BashOperator(
task_id = 'complete',
depends_on_past = False,
bash_command = 'echo "complete~!"',
trigger_rule = TriggerRule.NONE_FAILD
)
dummy_1 = DummyOperator(task_id = "path1")
- t1
- t1의 task는 bash 명령어나 스크립트를 실행하는데 사용되는 bashoperator로 정의되고 있다.
- 이 task는 bash 명령어인 'date'를 실행하여 현재 날짜를 출력해준다.
- t2
- branch operator를 통해 branch 작업을 정의한다.
- 이 task는 앞서 정의한 random_branch_path를 호출하여 1과 2중 하나의 숫자를 뽑아 1이면 task_id 가 "path1" 인 dummy_1으로 , 2이면 task_id 가 "my_name_en"인 t4로 간다.
- depends_on_past 의 기본값은 True이다. 즉, 이전작업인 t1이 실패하면 이 작업은 실행되지 않는다.
- t3
- bash operator로 정의되어 "안녕하세요 "를 출력하는 bash 명령어를 실행한다.
- depends_on_past = False 로 설정되어 이전 작업의 성공여부와 상관없이 이 작업은 항상 실행된다.
- t4
- 마찬가지로 이 작업은 "Hi"를 출력하는 bash 명령어를 실행한다.
- depends_on_past = False 로 설정되어 이전 작업의 성공여부와 상관없이 이 작업은 항상 실행된다.
- complete
- complete~! 를 출력하는 bash명령어를 수행한다.
- depends_on_past = False 로 설정되어 이전 작업의 성공여부와 상관없이 이 작업은 항상 실행된다.
- TriggerRule.NONE_FAILED 로 설정되어 어떤 작업이 실패하더라도 실행된다.
4. task relationship 설정
t1 >> t2 >> dummy_1 >> t3 >> complete
t1 >> t2 >> t4 >> complete
t2는 branch역할을 하기 때문에 t2를 기준으로 relationship을 2개로 나누게 된다.
전체 코드는 다음과 같다.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import BranchPythonOperator
from airflow.utils.trigger_rule import TriggerRule
def random_branch_path():
from random import randint
return "path1" if randint(1, 2) == 1 else "my_name_en"
dag_args = {
"dag_id" : "BranchOperator",
"default_args" : {
"owner" : "minseo",
"start_date" : datetime(2023, 1, 1),
"retries" : 1, # 작업이 실패할 경우 재시도횟수
"retry_delay" : timedelta(minutes=5) #작업을 재시도할 때 까지의 대기시간 5분으로 설정
},
"description" : "Minseo's example DAG",
"schedule_interval" : timedelta(days=1) #스케줄 주기는 1일
}
with DAG(**dag_args) as dag:
t1 = BashOperator(
task_id='print_date',
bash_command='date',
)
t2 = BranchPythonOperator(
task_id='branch',
python_callable=random_branch_path,
)
t3 = BashOperator(
task_id='my_name_ko',
depends_on_past=False,
bash_command='echo "안녕하세요".',
)
t4 = BashOperator(
task_id='my_name_en',
depends_on_past=False,
bash_command='echo "Hi"',
)
complete = BashOperator(
task_id='complete',
depends_on_past=False,
bash_command='echo "complete~!"',
trigger_rule=TriggerRule.NONE_FAILED,
)
dummy_1 = DummyOperator(task_id="path1")
t1 >> t2 >> dummy_1 >> t3 >> complete
t1 >> t2 >> t4 >> complete
이제 다시 airflow scheduler 를 실행시켜본다.
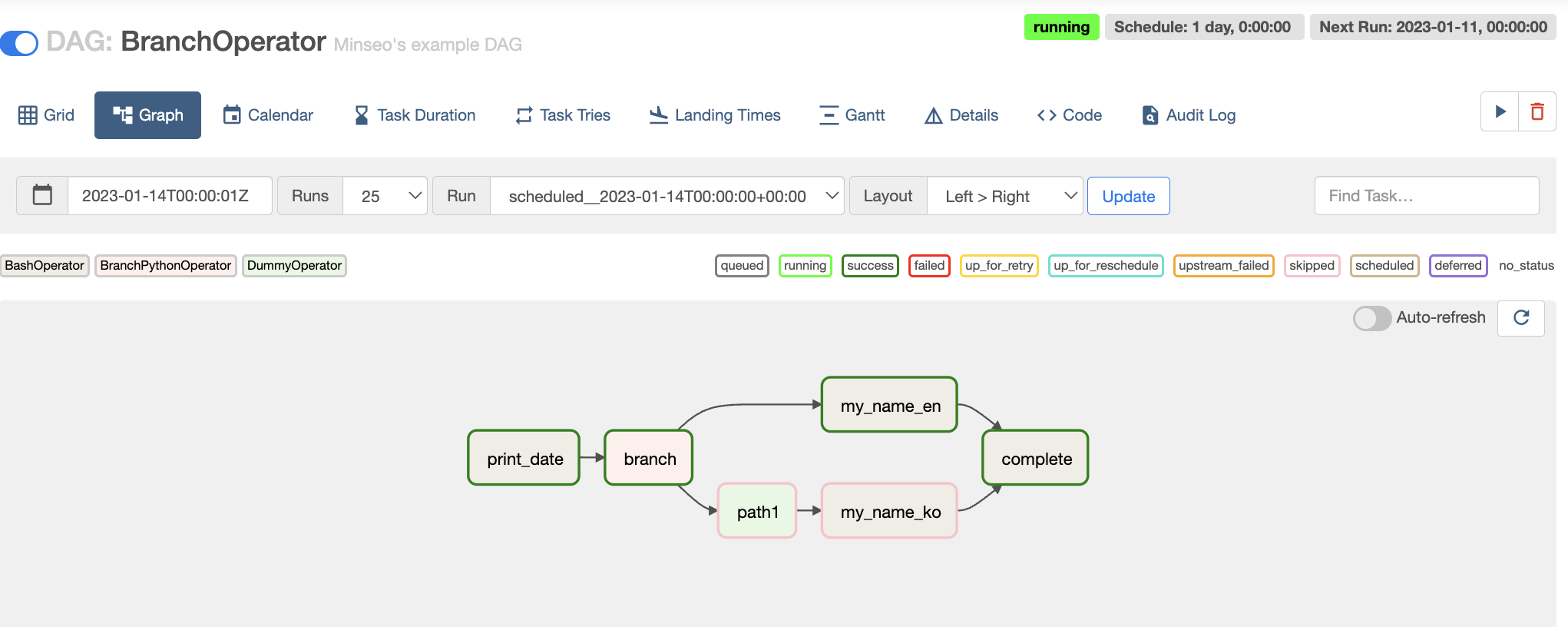
위의 경로는 success 상태로 초록색 테두리를 확인할 수 있고 밑에 경로는 skipped된 분홍색 테두리를 확인할 수 있다.
즉, random number 2가 나와서 task2에서 분기되어 t4 >> complete 경로로 가게 된 것이다.
이렇게 branchoperator로 원하는 조건을 설정하고 이에 따라 task의 경로를 설정할 수 있다.
Airflow Python operator 예제
airflow에는 여러가지 Python operator가 있다.
- bash operator
- dummy operator
- email operator
- jdbc operator
이번에는 airflow Xcom과 operator를 이용하는 예제를 살펴본다.
Airflow Xcom(cross-communication)이란?
airflow의 task는 독립적으로 수행되기 때문에 서로 통신할 수 있는 방법이 없다.
하지만 task를 구성하다보면 이전 task의 결과를 다음 task에 전달하거나 등의 작업의 필요성이 나온다.
이런 부분을 해결해주는 것이 Xcom이다.
Xcom은 적은 양의 메세지를 주고받는데의 용도이기 떄문에 pandas dataframe과 같은 large value에는 적합하지 않다.
Xcom의 특징을 정리하면 다음과 같다.
- 적은양의 데이터를 통신
- task_id, dag_id, key로 구분
- xcom_push, xcom_pull을 이용해 storage 에 push, pull 되어짐
Pythonoperator, Xcom을 활용한 airflow 예제 코드를 살펴보자
1. 함수셋팅
필요 라이브러리 셋팅 후 python task 구성을 위한 함수를 셋팅한다.
def random_branch_path():
from random import randint
return "cal_a_id" if randint(1,2) == 1 else "cal_m_id"
def calc_add(x,y, **kwargs) :
result = x + y
print("x + y : ", result)
kwargs['task_instance'].xcom_push(key='calc_result', value = result) ##계산 결과를 다른 task와 공유
return "calc add"
def calc_mul(x,y, **kwargs) :
result = x * y
print("x * y : ", result)
kwargs['task_instance'].xcom_push(key='calc_result', value = result)
print("*" * 100)
print(kwargs)
def print_result(**kwargs) :
r = kwargs["task_instance"].xcom_pull(key='calc_result')
print("message : ", r)
print("*" * 100)
print(kwargs)
def end_seq():
print("end")
- random_branch_path()
- 분기를 설정하기 위한 함수이다.
- 1이면 task_id가 "calc_a_id"인 task로 2이면 task_id 가 "calc_m_id"인 task로 간다.
- calc_add, mul ()
- x, y를 인자로 받아 더하고 곱한다.
- task instance와 관련된 인수를 받아 xcom_push로 calc_result라는 키에 결과를 저장한다.
- print_result
- 결과를 출력하는 함수로 xcom_pull 로 저장된 결과 값을 출력한다.
- end_seq()
- sequence가 끝났다는 end 를 출력
xcom_push, xcom_pull로 key에 결과를 저장하고 불러오면서 task끼리 결과를 공유할 수 있게 되는 것이다.
2. DAG 객체 설정
with DAG( **dag_args ) as dag:
start = BashOperator(
task_id = 'start',
bash_command = 'echo "start!"',
)
branch = BranchPythonOperator(
task_id = 'branch',
python_callable = random_branch_path,
)
calc_add = PythonOperator(
task_id = 'cal_a_id',
python_callable = calc_add,
op_kwargs = {'x' : 10, 'y': 4}
)
calc_mul = PythonOperator(
task_id = 'calc_m_id',
python_callable = calc_mul,
op_kwargs = {'x' : 10, 'y': 4}
)
msg = PythonOperator(
task_id = 'msg',
python_callable = print_result,
trigger_rule = TriggerRule.NONE_FAILED
)
complete_py = PythonOperator(
task_id = 'complete_py',
python_callable = end_seq,
trigger_rule = TriggerRule.NONE_FAILED
)
complete = BashOperator(
task_id = 'complete_bash',
depends_on_past = False,
bash_command = 'echo "compltete~!"',
trigger_rule = TriggerRule.NONE_FAILED
)
위에서 설명했던 방식과 유사하기에 설명은 생략한다.
op_kwargs 의 경우 calc_add, mul을 할 때 변수의 값을 할당하는 역할을 한다.
3. DAG task relationship 구성
start >> branch >> calc_add >> msg >> complete_py >> complete
start >> branch >> calc_mul >> msg >> complete
msg 로 calc_add,mul된 결과값을 출력해준 뒤 complete task를 수행하게 된다.
해당 명령어로 task들간의 relationship을 확인할 수 있다.
airflow tasks list {DAG id} --tree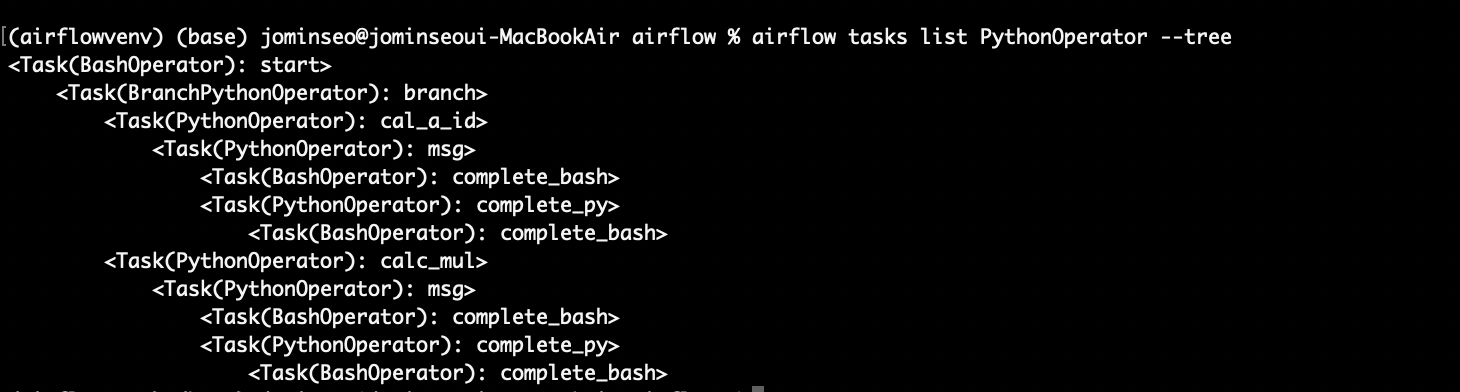
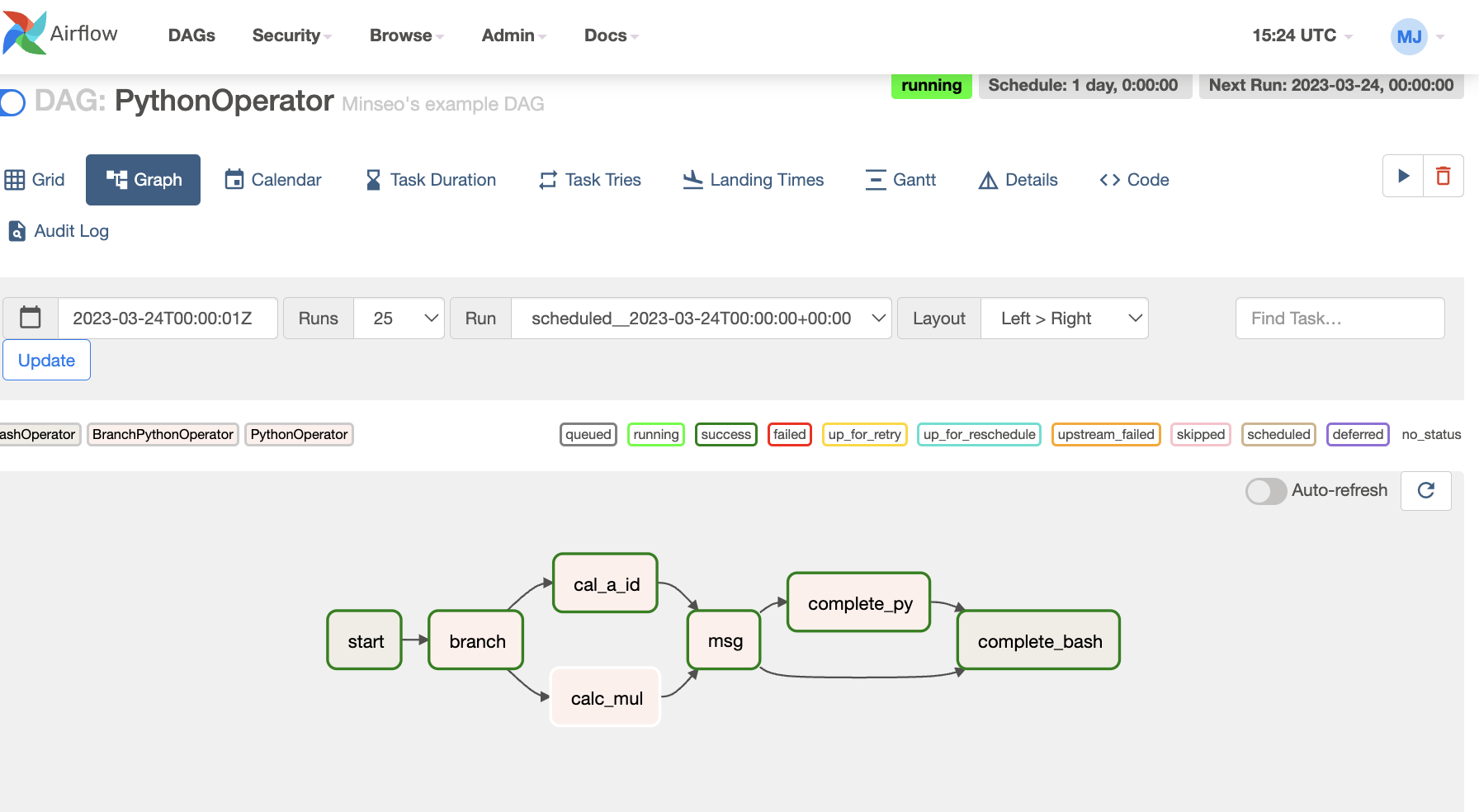
그래프를 확인해보면 cal_a_id 쪽으로 프로세스가 진행 된 것을 확인할 수 있다.
(cal_m_id 라고 calc_mul task를 지정해줬어야했는데 오타가 났다.. 🥲)
III. Machine learning 예제
kaggle 의 타이타닉 데이터를 활용하여 머신러닝 코드를 airflow dag에 활용해본다.
파일 구조는 다음과 같다.
관련 코드는 출처에 있는 깃허브 코드를 활용하였다.
https://github.com/lsjsj92/airflow_tutorial/blob/main/MLproject/titanic.py
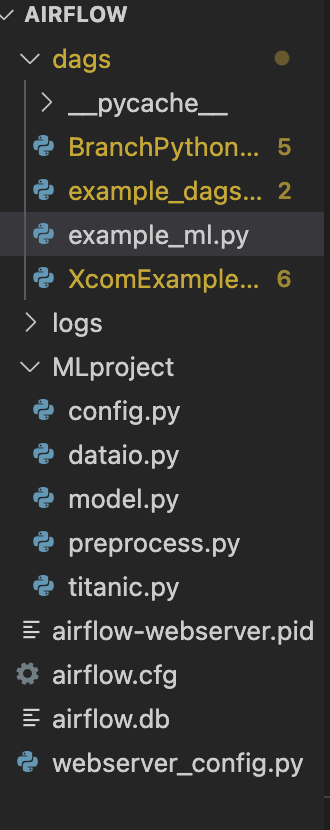
ML 과 관련된 파일 구성은 다음과 같다.
- config.py
- 머신러닝을 돌리기 위한 각종 셋팅 값 설정
- dataio.py
- 데이터를 읽어오거나 필요 데이터를 추출하는 작업을 수행
- model.py
- 머신러닝 모델, 훈련수행
- titanic.py
- 메인 코드 파일
1. Machine Learning 구성
여기서 메인 코드는 titanic.py이기 때문에 해당 코드를 살펴보자.
#titanic.py
import pandas as pd
from MLproject.preprocess import TitanicPreprocess
from MLproject.config import PathConfig
from MLproject.dataio import DataIOSteam
from MLproject.model import TitanicModeling
class TitanicMain(TitanicPreprocess, PathConfig, TitanicModeling, DataIOSteam):
def __init__(self):
TitanicPreprocess.__init__(self)
PathConfig.__init__(self)
TitanicModeling.__init__(self)
DataIOSteam.__init__(self)
def prepro_data(self, f_name, **kwargs):
# fname = train.csv
data = self.get_data(self.titanic_path, f_name)
data = self.run_preprocessing(data)
data.to_csv(f"{self.titanic_path}/prepro_titanic.csv", index=False)
kwargs['task_instance'].xcom_push(key='prepro_csv', value=f"{self.titanic_path}/prepro_titanic")
return "end prepro"
def run_modeling(self, n_estimator, flag, **kwargs):
# n_estimator = 100
f_name = kwargs["task_instance"].xcom_pull(key='prepro_csv')
data = self.get_data(self.titanic_path, f_name, flag)
X, y = self.get_X_y(data)
model_info = self.run_sklearn_modeling(X, y, n_estimator)
kwargs['task_instance'].xcom_push(key='result_msg', value=model_info)
return "end modeling"
titanic.py에는 데이터를 수집, 전처리, 모델 훈련의 일련의 과정이 담겨있다.
총 2개의 함수로 구성되어 있으며 각 함수는 Airflow DAG 파일 안에서 각 task가 수행하게 된다.
타이타닉 머신러닝 코드의 동작 순서는 다음과 같다.
1. 최초 타이타닉 데이터 로드 (prepro_data)
2. 타이타닉 데이터 전처리 및 prepro_csv로 저장 (prepro_data)
3. preprocessing을 거친 파일의 경로를 airflow xcom에 저장(prepro_data)
4. machine learning 모델링 수행 (run_modeling)
5. airflow xcom에 저장된 전처리 데이터를 가져옴 (run_modeling)
6. 전처리된 데이터 load (run_modeling)
7. 모델 훈련 (run_modeling)
8. model 정보 airflow xcom에저장 (run_modeling)
9. 종료
2. DAG 객체 구성
해당 머신러닝을 airflow를 통해 구동시키기 위한 예제를 살펴보자
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.utils.trigger_rule import TriggerRule
import sys, os
sys.path.append(os.getcwd())
from MLproject.titanic import *
titanic = TitanicMain()
def print_result(**kwargs):
r = kwargs["task_instance"].xcom_pull(key='result_msg')
print("message : ", r)
default_args = {
'owner': 'owner-name',
'depends_on_past': False,
'email': ['your-email@g.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=30),
}
dag_args = dict(
dag_id="tutorial-ml-op",
default_args=default_args,
description='tutorial DAG ml',
schedule_interval=timedelta(minutes=50),
start_date=datetime(2022, 2, 1),
tags=['example-sj'],
)
with DAG( **dag_args ) as dag:
start = BashOperator(
task_id='start',
bash_command='echo "start!"',
)
prepro_task = PythonOperator(
task_id='preprocessing',
python_callable=titanic.prepro_data,
op_kwargs={'f_name': "train"}
)
modeling_task = PythonOperator(
task_id='modeling',
python_callable=titanic.run_modeling,
op_kwargs={'n_estimator': 100, 'flag' : True}
)
msg = PythonOperator(
task_id='msg',
python_callable=print_result
)
complete = BashOperator(
task_id='complete_bash',
bash_command='echo "complete~!"',
)
start >> prepro_task >> modeling_task >> msg >> complete
여기서는 3개의 python operator 를 사용하여 3개의 task를 정의한다.
- prepro_task
- 타이타닉 데이터 전처리를 수행하는 DAG task
- titanic.py 에 있는 prepro_data 함수를 호출
- prepro_data 함수에서 사용하는 parameter f_name 을 op_kwargs 로 전달 (train 이라는 파일이름에서 데이터를 가져오게 되는 것)
- modeling_task
- 전처리 된 타이타닉 데이터를 활용해 머신러닝 모델링 수행
- run_modeling 함수 호출
- rum_modeling에서 사용하는 n_estimator, flag를 op_kwargs로 보내줌
- msg
- 앞서 모델링을 통해 받은 결과 값을 출력
3. 실행 결과
CLI를 통해 DAG 가 제대로 등록되었는지 확인해본다.

web ui 의 graph로 확인해보자
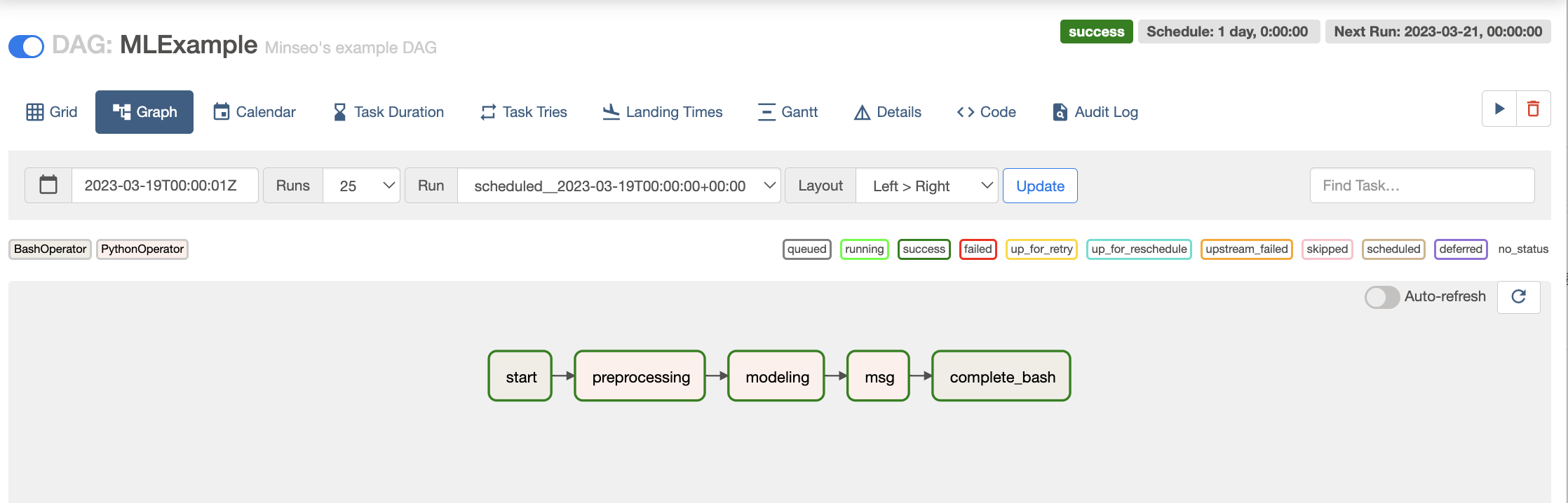
간트차트로도 어떤 task가 수행하는데 얼마나 걸렸는지 알 수 있다.
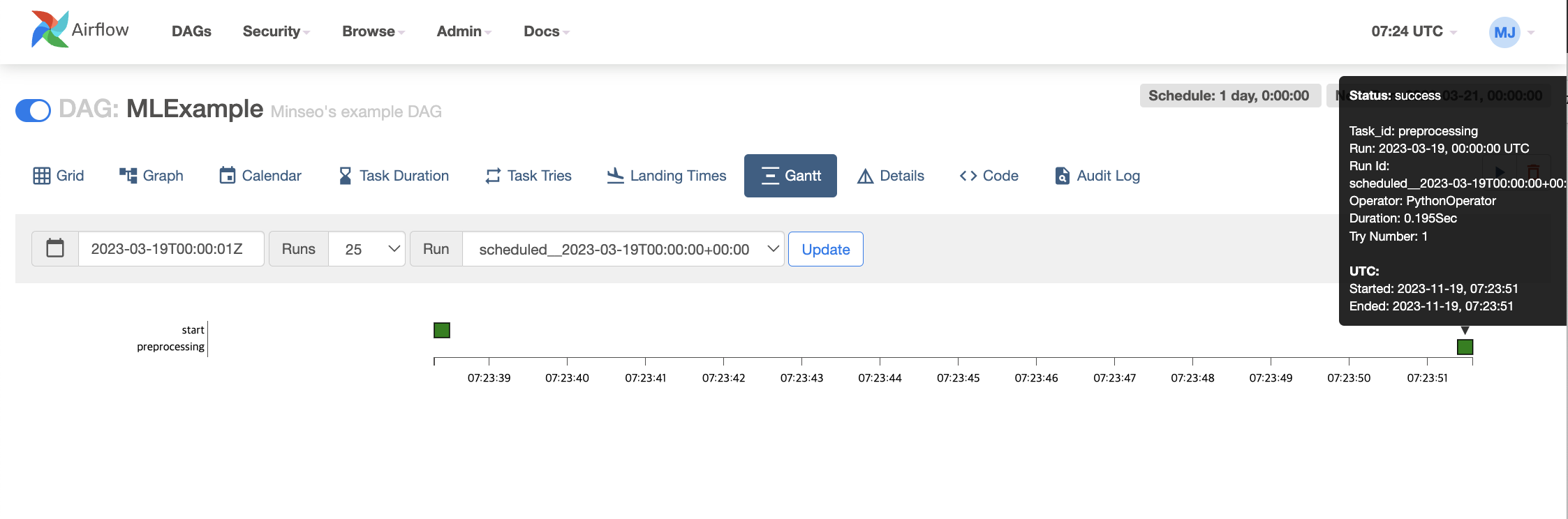
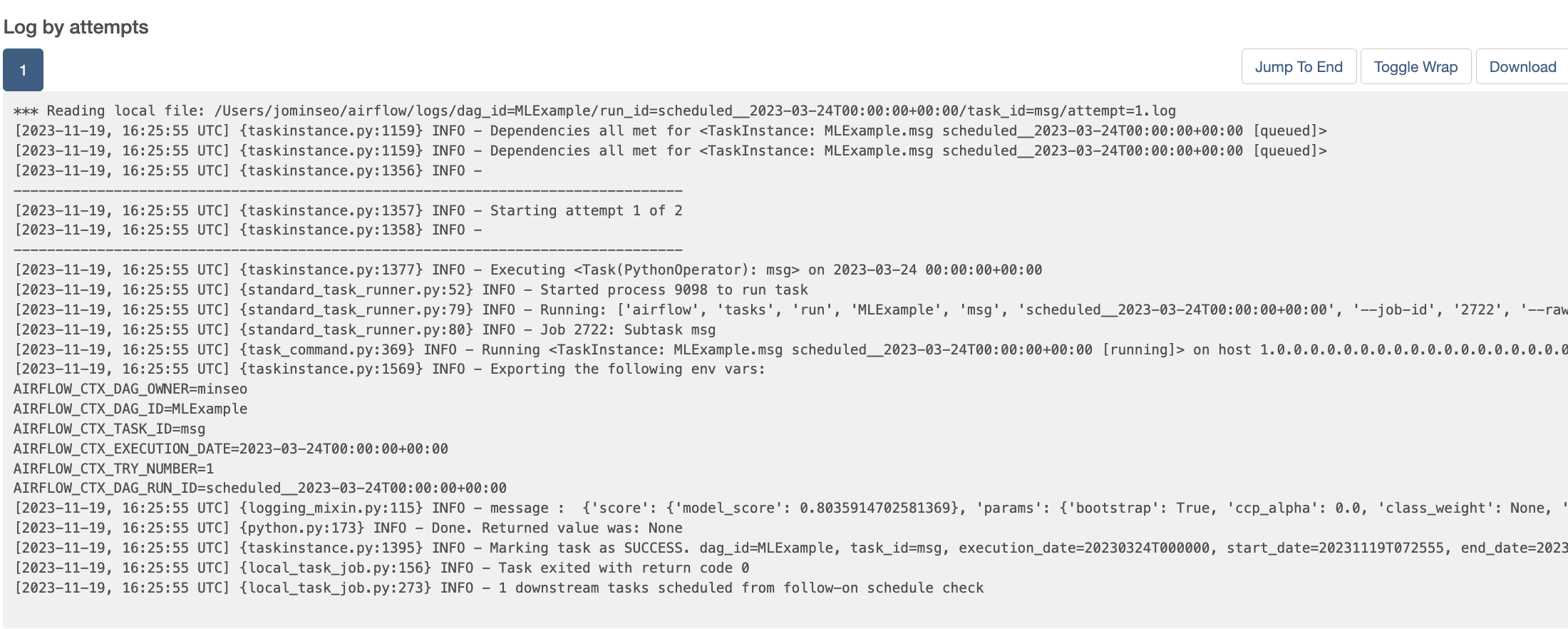
msg task의 로그를 통해서 model의 score과 parameter값이 정상적으로 출력되는 것을 확인할 수 있다.
참고 자료
https://lsjsj92.tistory.com/631
Apache 에어플로우(Airflow) 시작하기 - Airflow란?, Airflow 설치 및 기본 예제
포스팅 개요 본 포스팅은 Apache Airflow(에어플로우)에 대해서 정리하는 Airflow 시리즈 포스팅입니다. Airflow 포스팅에서는 아래와 같은 순서로 Airflow에 대해서 정리해보려고 합니다. Airflow란 무엇인
lsjsj92.tistory.com
'데이터 > 데이터 엔지니어링' 카테고리의 다른 글
| [Apache Airflow] ETL 프로젝트 #2 (Slack 메신저 봇 만들기) (0) | 2023.12.02 |
|---|---|
| [Apache Airflow] ETL 프로젝트 #1 (ETL 파이프라인 구축) (1) | 2023.11.25 |
| [Chapter07] OpenSearch CRUD 실습 (1) | 2023.10.07 |
| [Chapter 06] 분산시스템의 이해, Zookeeper (1) | 2023.10.01 |
| [Chapter 05 | Observability] Grafana로 대시보드 구축하기 (0) | 2023.09.23 |