
저번주에 학습한 이론, 예제를 바탕으로 공모전 대회 정보를 수집하는 ETL 파이프라인을 구축해보겠습니다.🔧
개발환경
OS : ubuntu 22.04
Python 3.11
Airflow 2.3.0
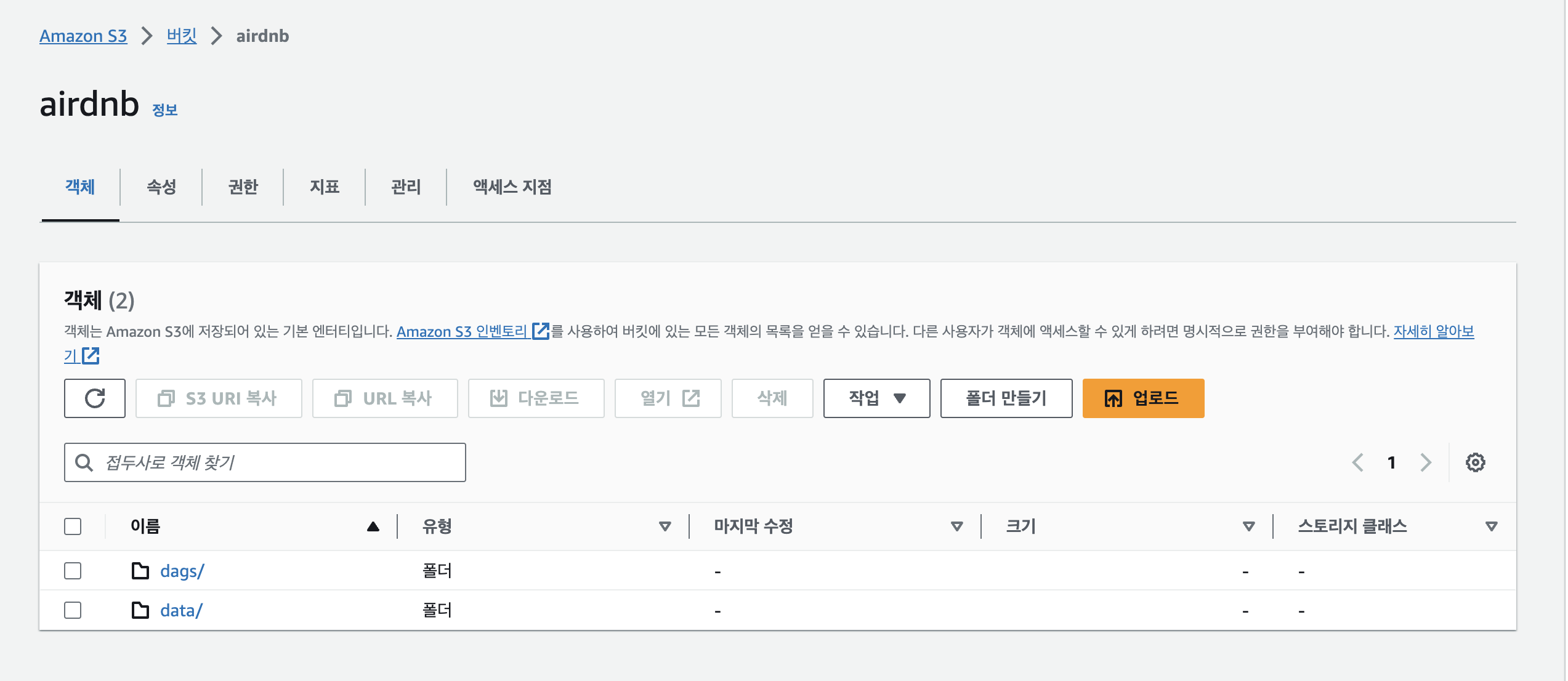
1. Amazon S3 생성
버킷 내의 폴더 구성은 dag 파일을 올려두는 dags, 데이터를 저장하는 data로 구성하였다.
2. AWS EC2 환경 셋업
# Virtualenv 패키지 설치
sudo apt-get install virtualenv
#가상환경 폴더 생성
virtualenv {가상환경폴더이름}
#가상환경 실행
source {가상환경폴더이름}/bin/activate# python, 필요 라이브러리 설치
# 파이썬 3.11 설치
sudo apt-get install python3.11
# pip 설치
sudo apt install python3-pip# 경로 및 환경변수 설정
export AIRFLOW_HOME=~/airflow
export AIRFLOW_VERSION=2.7.3
export PYTHON_VERSION=3.11
# airflow설치
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"# db 초기화
airflow db init#계정 생성
airflow users create \
--username admin \
--firstname minseo \
--lastname Jo \
--role Admin \
3. DAG 객체 생성
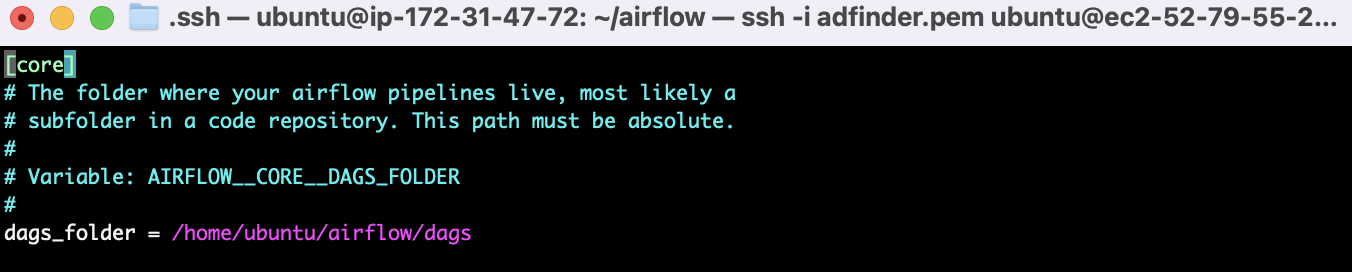
#터미널에서 airflow.cfg 파일 확인
vi airflow.cfg
airflow.cfg 파일에서 dag folder 를 지정할 수 있다.
내가 만들 DAG(workflow)는 공모전 대회 정보 크롤링을 수행하는 task를 통해 정의된다.
따라서 크롤링 함수를 따로 작성하여 이 함수를 실행할 task를 지정해야한다.
크롤링을 위한 필요 라이브러리를 가상환경에 설치해준다.
# bs4설치
sudo apt-get install python3-bs4
#파서 설치
sudo apt-get install python3-lxml
이제 해당 폴더에 dag 파일을 작성해보자!
# dag.py 파일 생성
vi contest_dags.py
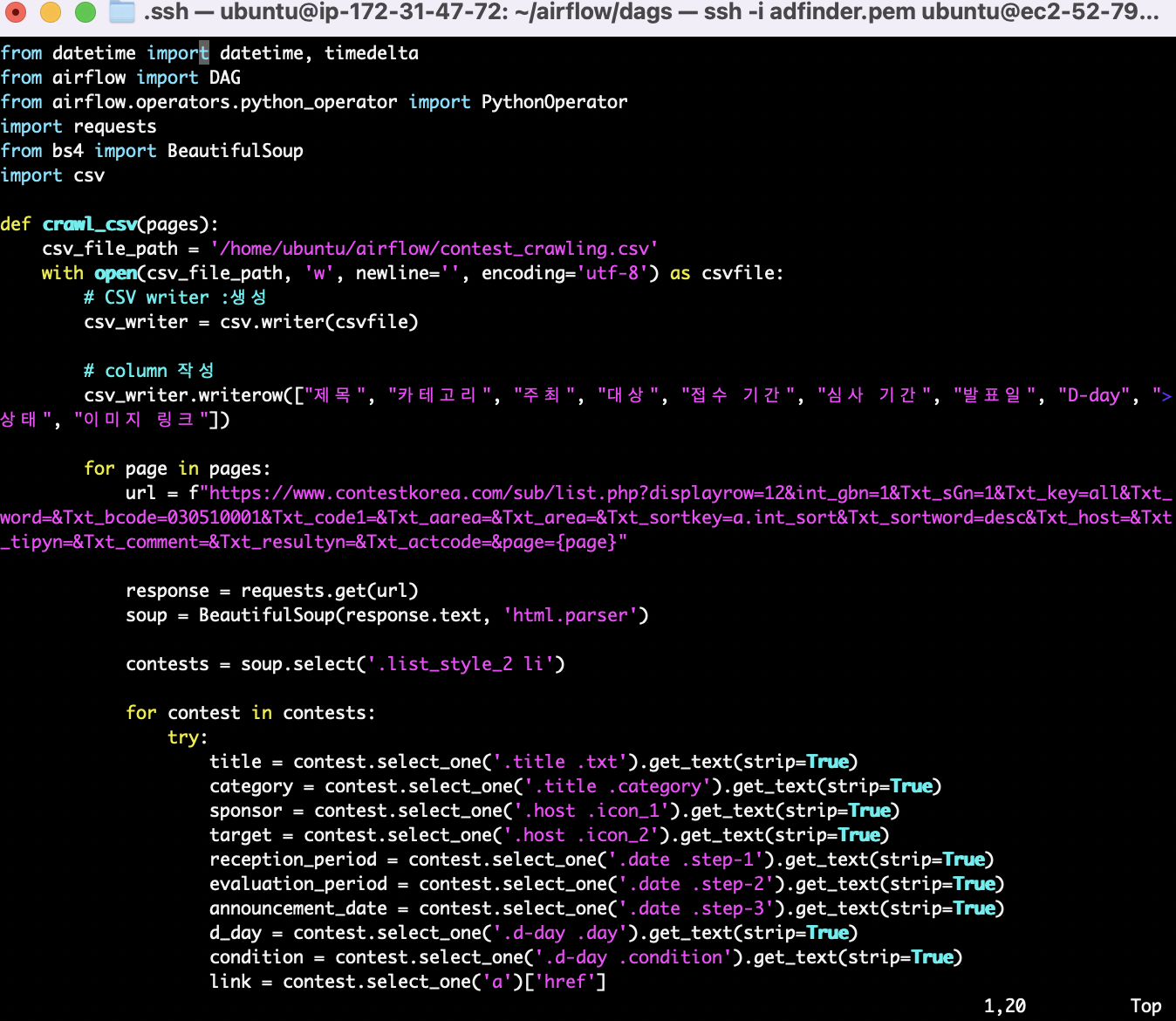
크롤링 코드는 다음과 같다.
S3에 .csv 파일 형태로 저장해야하기 때문에 csv 파일에 작성할 수 있도록 코드를 작성했다.
import requests
from bs4 import BeautifulSoup
import csv
def crawl_csv(pages):
# csv 파일에 쓰기 모드
csv_file_path = '/home/ubuntu/airflow/contest_crawling.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csvfile:
# csv 작성을 위한 writer 생성
csv_writer = csv.writer(csvfile)
# column 작성
csv_writer.writerow(["제목", "카테고리", "주최", "대상", "접수 기간", "심사 기간", "발표일", "D-day", "상태", "이미지 링크"])
for page in pages:
url = f"https://www.contestkorea.com/sub/list.php?displayrow=12&int_gbn=1&Txt_sGn=1&Txt_key=all&Txt_word=&Txt_bcode=030510001&Txt_code1=&Txt_aarea=&Txt_area=&Txt_sortkey=a.int_sort&Txt_sortword=desc&Txt_host=&Txt_tipyn=&Txt_comment=&Txt_resultyn=&Txt_actcode=&page={page}"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
contests = soup.select('.list_style_2 li')
for contest in contests:
try:
title = contest.select_one('.title .txt').get_text(strip=True)
category = contest.select_one('.title .category').get_text(strip=True)
sponsor = contest.select_one('.host .icon_1').get_text(strip=True)
target = contest.select_one('.host .icon_2').get_text(strip=True)
reception_period = contest.select_one('.date .step-1').get_text(strip=True)
evaluation_period = contest.select_one('.date .step-2').get_text(strip=True)
announcement_date = contest.select_one('.date .step-3').get_text(strip=True)
d_day = contest.select_one('.d-day .day').get_text(strip=True)
condition = contest.select_one('.d-day .condition').get_text(strip=True)
link = contest.select_one('a')['href']
link = "https://www.contestkorea.com/sub/" + link
response_b = requests.get(link)
soup_b = BeautifulSoup(response_b.text, 'html.parser')
image_link = soup_b.select_one('div.clfx>div.img_area > div > img')['src']
image_link = 'https://www.contestkorea.com' + image_link
# 한 행씩 csv 파일에 추가
csv_writer.writerow([title, category, sponsor, target, reception_period, evaluation_period, announcement_date, d_day, condition, image_link])
except:
pass
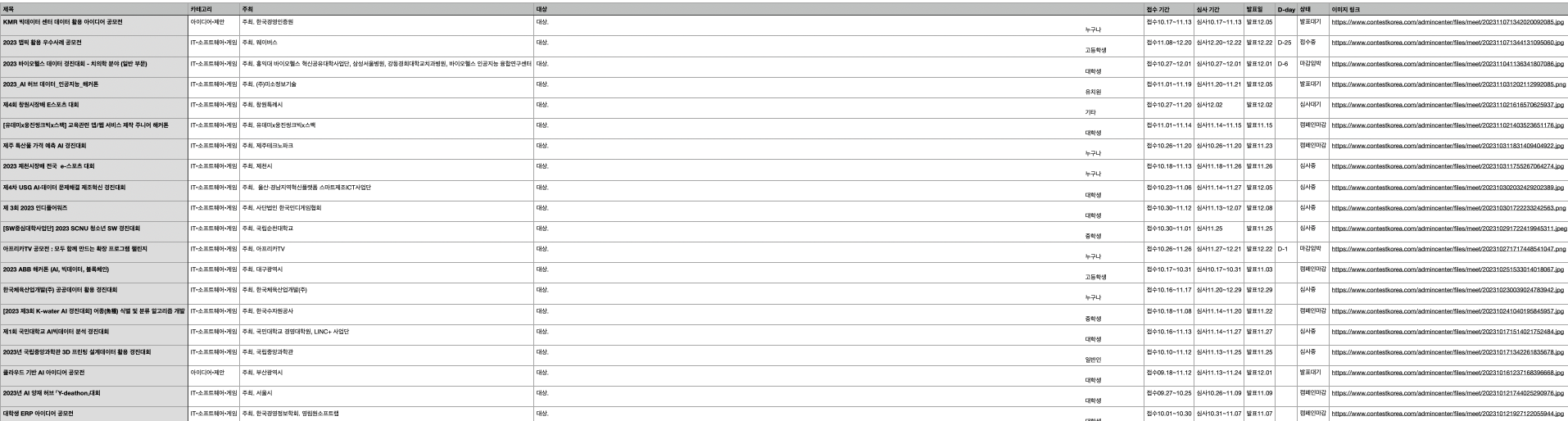
csv파일에 저장되는 형태는 다음과 같다.
이제 이 함수를 수행하는 task로 구성된 DAG 코드를 작성해본다.
크롤링 후 적재까지만 진행하면 되는작업이라 task는 한 개로만 설정했다. (하나 뿐이라 뭔가 이상?하지만)
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
dag_args = {
"dag_id": "ContestDAG",
"default_args": {
"owner": "minseo",
"start_date": datetime(2023, 1, 1),
"retries": 1,
"retry_delay": timedelta(minutes=5)
},
"description": "Minseo's contest DAG",
"schedule_interval": timedelta(days=1)
}
# 크롤링할 양(=페이지 수)설정
pages = list(range(2, 4))
with DAG(**dag_args) as dag:
crawler = PythonOperator(
task_id='crawl_csv',
python_callable=crawl_csv,
op_kwargs={'pages': pages},
provide_context=True
)
일단 적재까지 정상적으로 되나 테스트해보고자 크롤링하는 양은 조금만 설정했다. (스케줄링 시간이 너무 오래걸린다ㅜ)
전체 contest_crawler.py dag코드는 다음과 같다.
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
import requests
from bs4 import BeautifulSoup
import csv
def crawl_csv(pages):
# csv 파일을 쓰기 모드로 열기
csv_file_path = '/home/ubuntu/airflow/contest_crawling.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csvfile:
# csv writer 생성
csv_writer = csv.writer(csvfile)
# column 작성
csv_writer.writerow(["제목", "카테고리", "주최", "대상", "접수 기간", "심사 기간", "발표일", "D-day", "상태", "이미지 링크"])
for page in pages:
url = f"https://www.contestkorea.com/sub/list.php?displayrow=12&int_gbn=1&Txt_sGn=1&Txt_key=all&Txt_word=&Txt_bcode=030510001&Txt_code1=&Txt_aarea=&Txt_area=&Txt_sortkey=a.int_sort&Txt_sortword=desc&Txt_host=&Txt_tipyn=&Txt_comment=&Txt_resultyn=&Txt_actcode=&page={page}"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
contests = soup.select('.list_style_2 li')
for contest in contests:
try:
title = contest.select_one('.title .txt').get_text(strip=True)
category = contest.select_one('.title .category').get_text(strip=True)
sponsor = contest.select_one('.host .icon_1').get_text(strip=True)
target = contest.select_one('.host .icon_2').get_text(strip=True)
reception_period = contest.select_one('.date .step-1').get_text(strip=True)
evaluation_period = contest.select_one('.date .step-2').get_text(strip=True)
announcement_date = contest.select_one('.date .step-3').get_text(strip=True)
d_day = contest.select_one('.d-day .day').get_text(strip=True)
condition = contest.select_one('.d-day .condition').get_text(strip=True)
link = contest.select_one('a')['href']
link = "https://www.contestkorea.com/sub/" + link
response_b = requests.get(link)
soup_b = BeautifulSoup(response_b.text, 'html.parser')
image_link = soup_b.select_one('div.clfx>div.img_area > div > img')['src']
image_link = 'https://www.contestkorea.com' + image_link
# 한 행씩 csv 파일에 작성
csv_writer.writerow([title, category, sponsor, target, reception_period, evaluation_period, announcement_date, d_day, condition, image_link])
except:
pass
dag_args = {
"dag_id": "ContestDAG",
"default_args": {
"owner": "minseo",
"start_date": datetime(2023, 1, 1),
"retries": 1,
"retry_delay": timedelta(minutes=5)
},
"description": "Minseo's contest DAG",
"schedule_interval": timedelta(days=1)
}
# 크롤링할 양(=페이지 수)설정
pages = list(range(2, 4))
with DAG(**dag_args) as dag:
crawler = PythonOperator(
task_id='crawl_csv',
python_callable=crawl_csv,
op_kwargs={'pages': pages},
provide_context=True
)
4. webserver, scheduler 실행
#웹 서버 실행 명령
airflow webserver --port 8080
#스케줄러 실행
airflow scheduler
스케줄러를 실행시키면 내가 만든 DAG를 확인할 수 있다.
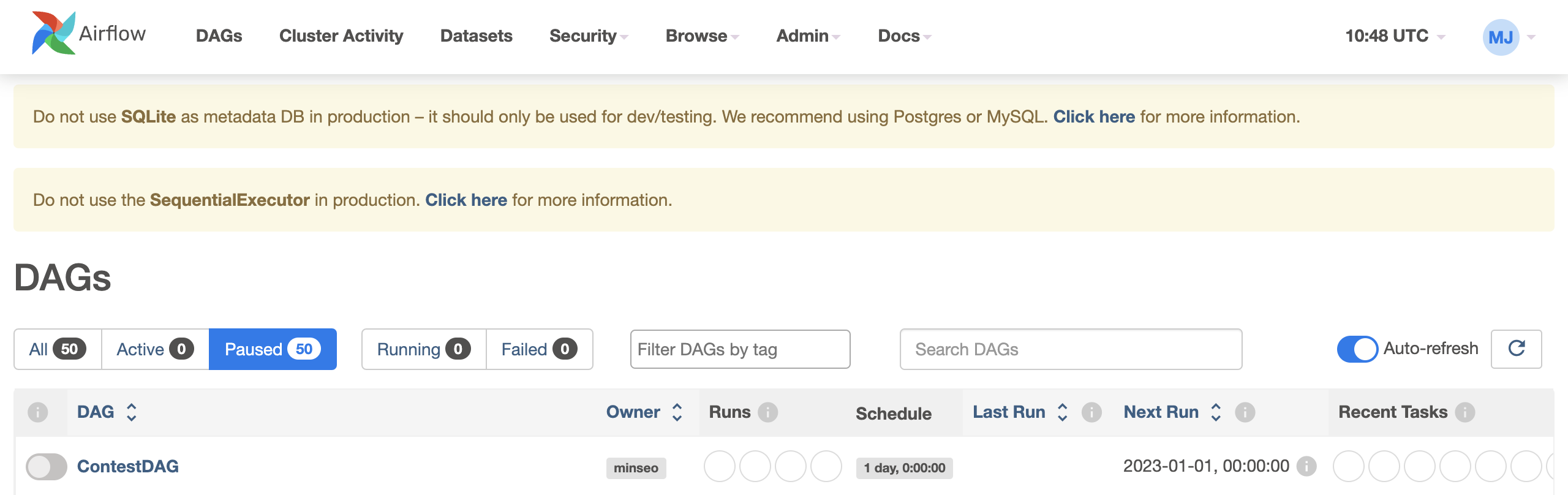
worker 일해라~!
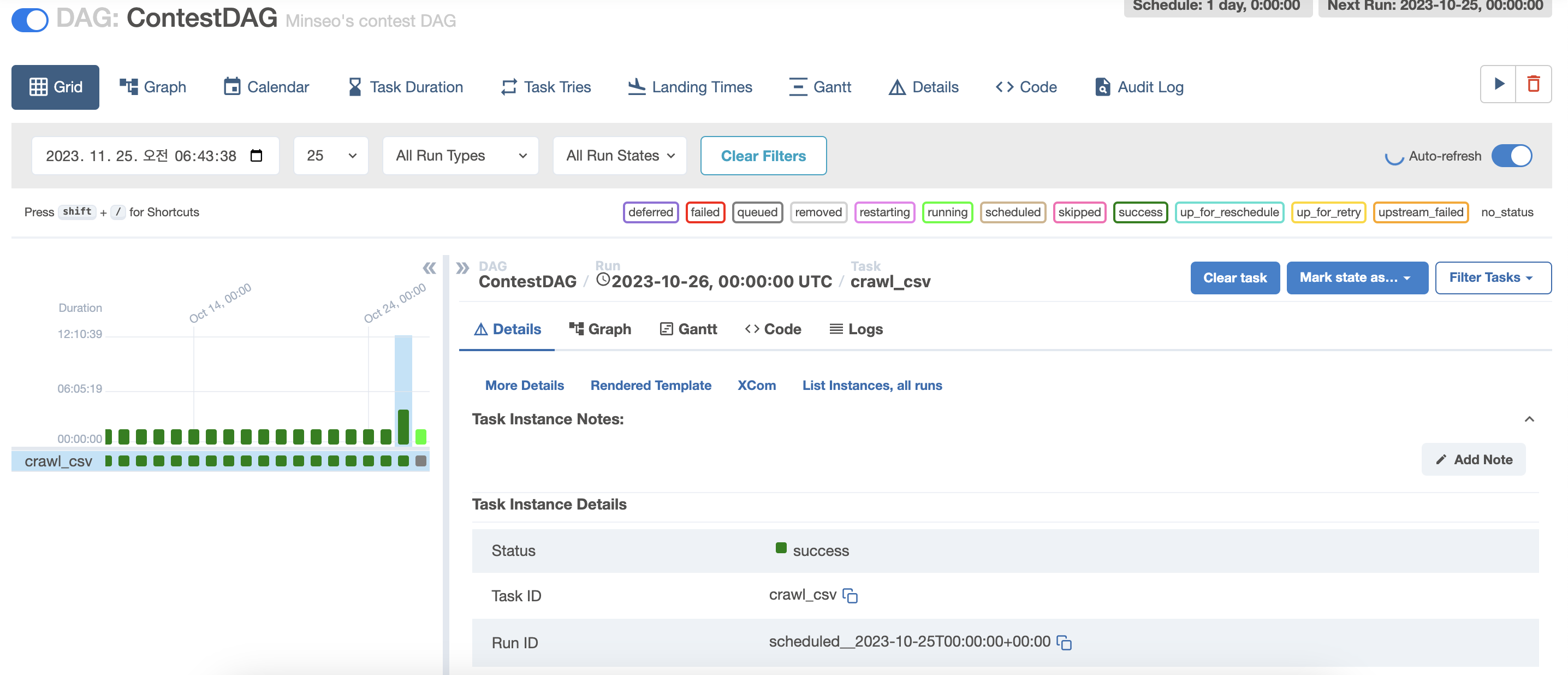
crawl_csv task 가 success 된 것을 확인할 수 있다.
contest_crawling.csv 파일 확인!

5. csv 파일 s3에 적재하기
airflow를 아마존 서비스와 연결하기 위해 가상환경에 amazon 패키지를 설치한다.
pip install apache-airflow-providers-amazon
connection type에서 Amazon Web Services 를 확인할 수 있다.
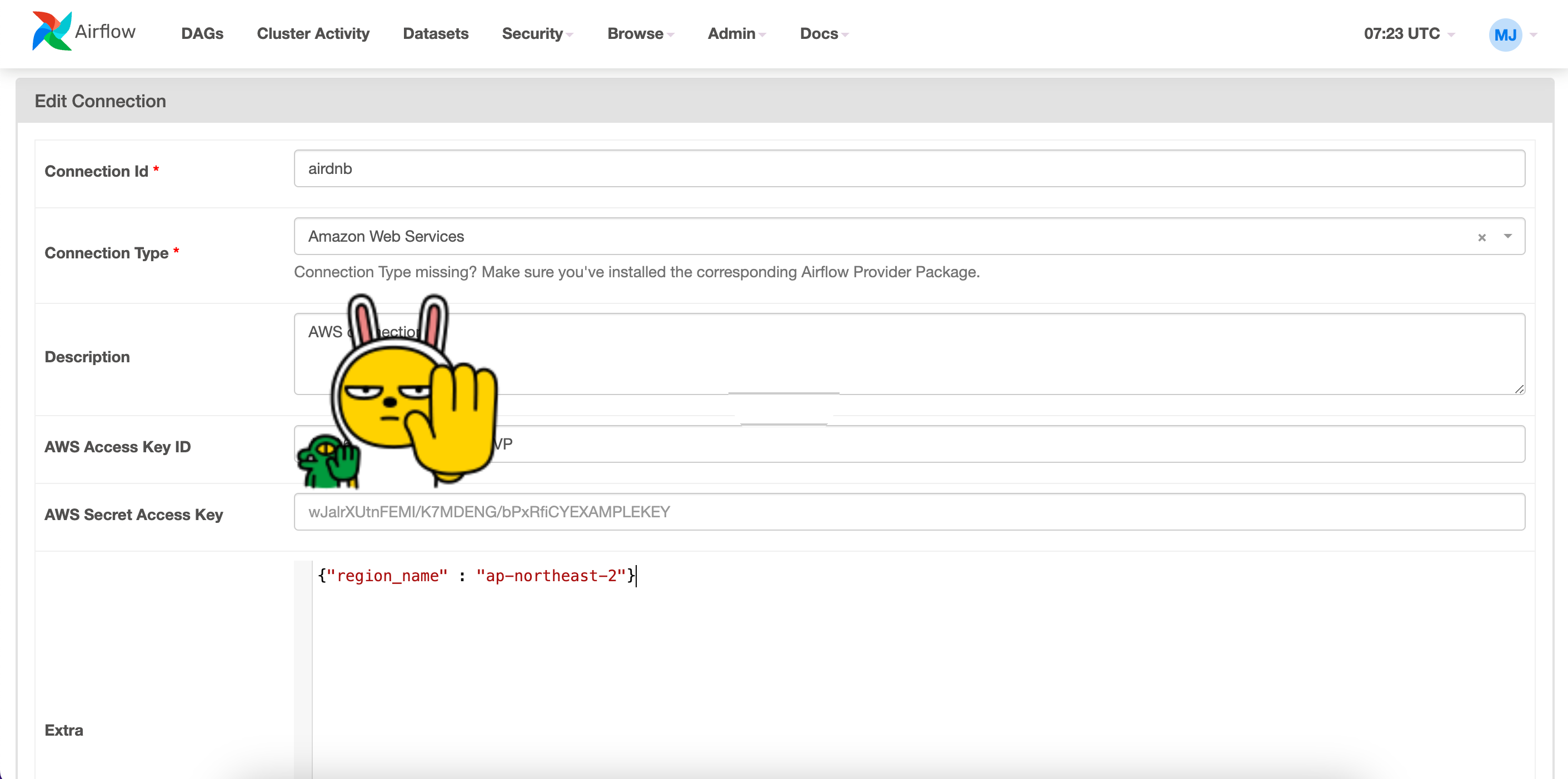
AWS IAM 액세스키 , 시크릿 액세스 키를 통해서 Airflow와 AWS 를 연결시킬 수 있는데,,
사용자를 만들어서 액세스키 발급 받았는데도 연결이 되지 않는다 😭
IAM 사용자 권한 설정을 잘못한 것 같은데,, AWS 서비스가 익숙하지 않아서 아직 해결 중이다.
다음 시리즈를 기대해주세요 ^3^
라고 끝내려고했으나
airflow.cfg 파일에서 test_connection 변수를 변경해주면되는거였다..ㅠ
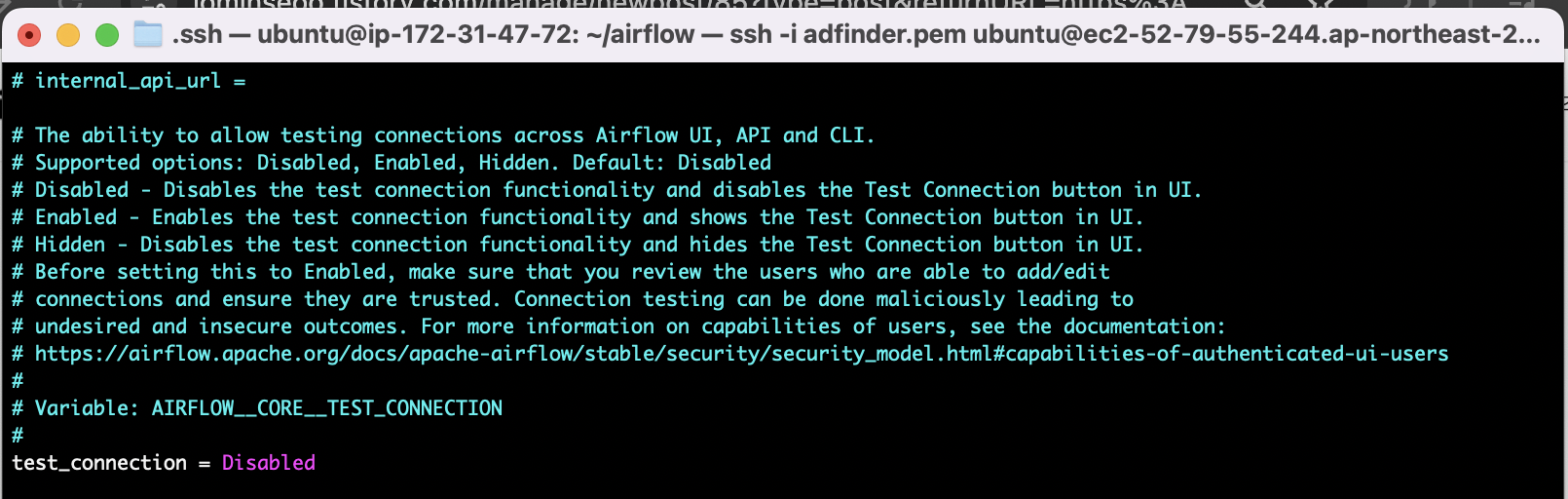
Enabled로변경해준다.
그리고 다시 aws 에서 발급받은 키를 입력하면..! 된다.. !
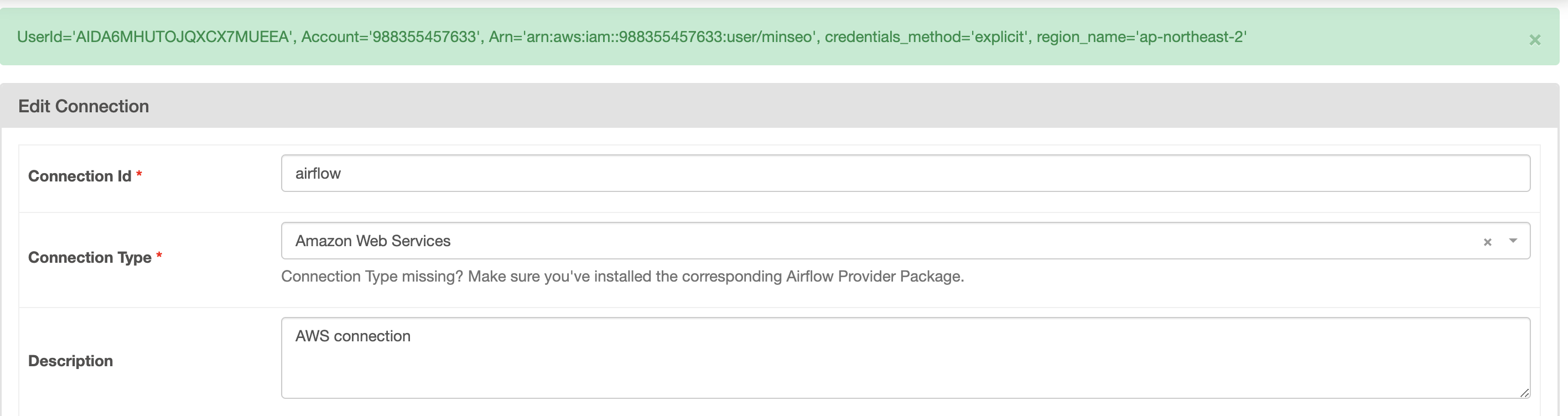
연결 성공!
이제 저장한 csv를 S3에 적재하는 DAG 파일 작성하고 올리면된다!
이건 다음 편에서 ~!
'데이터 > 데이터 엔지니어링' 카테고리의 다른 글
| [Apache Airflow] ETL 프로젝트 #3 (Prometheus + Grafana를 이용한 airflow 모니터링) (2) | 2023.12.03 |
|---|---|
| [Apache Airflow] ETL 프로젝트 #2 (Slack 메신저 봇 만들기) (0) | 2023.12.02 |
| [Apache Airflow] Airflow로 Branch, ML 예제 수행해보기 (1) | 2023.11.19 |
| [Chapter07] OpenSearch CRUD 실습 (1) | 2023.10.07 |
| [Chapter 06] 분산시스템의 이해, Zookeeper (1) | 2023.10.01 |