
학습 목표
1. 데이터셋 시뮬레이션
2. 기술통계로 데이터셋 요약 및 탐색
3. 간단한 시각화 방법 및 탐색
3.1 데이터 시뮬레이션
3.1.1 데이터 저장: 구조 설정
- 매장 체인에서 2개의 경쟁 제품에 대한 주별 총 판매량을 나타내는 데이터셋 만들기
- 구조, 가격과 함께 2년동안 20개 매장에서 두 제품의 판매 시뮬레이션인 데이터 구조를 생성
- shape로 행, 열 수와 데이터 구조 확인 -> NaN값 확인

- 각 상점 번호에서 해당 상점의 국가로 매핑되는 딕셔너리 생성



- astype()메서드로 store_sales.country, store_sales.store_num을 범주형으로 재정의

3.1.2 데이터 저장: 데이터 포인트 시뮬레이션
제품 1에 10%, 제품 2에 15%의 판촉 가능성 확률을 무작위로 할당
각 행에서 각 제품의 가격을 설정



- 판매 수치 시뮬레이션, 품목 판매량은 단위 수로 계산되므로 푸아송 분포를 사용해 개수 데이터 생성

제품 1의 매출은 제품 1의 로그가 제품 2의 로그 보다 낮은 비율만큼 더 높을 것이라고 가정

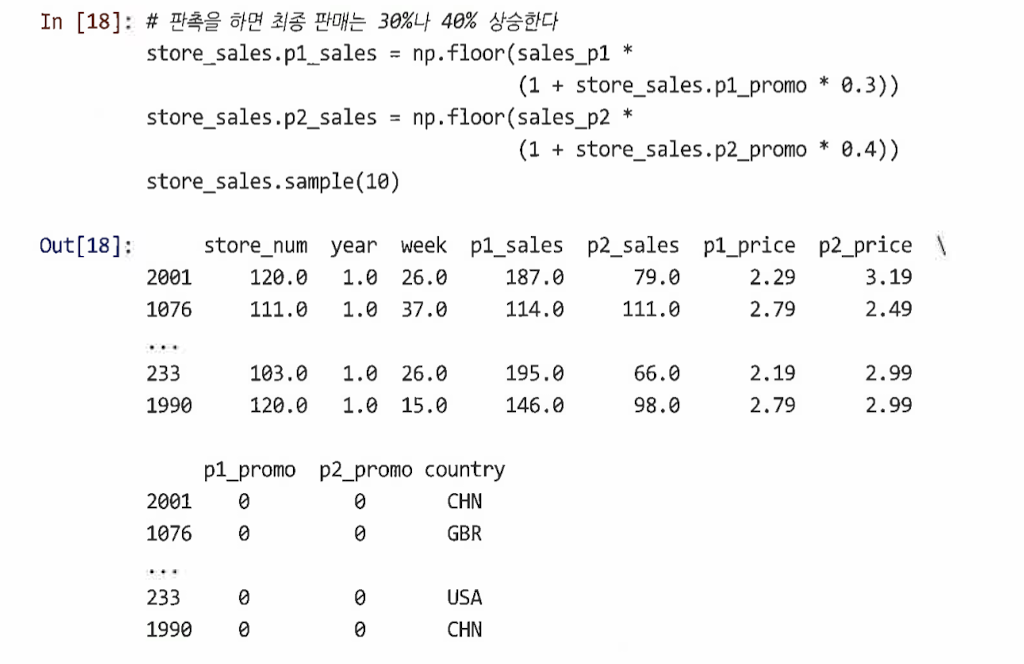
홍보될 때 매출 30~40% 증가한다고 가정
floor()함수로 주간 단위 판매에 대한 개수를 정수로 입력
3.2 변수를 요약하는 함수
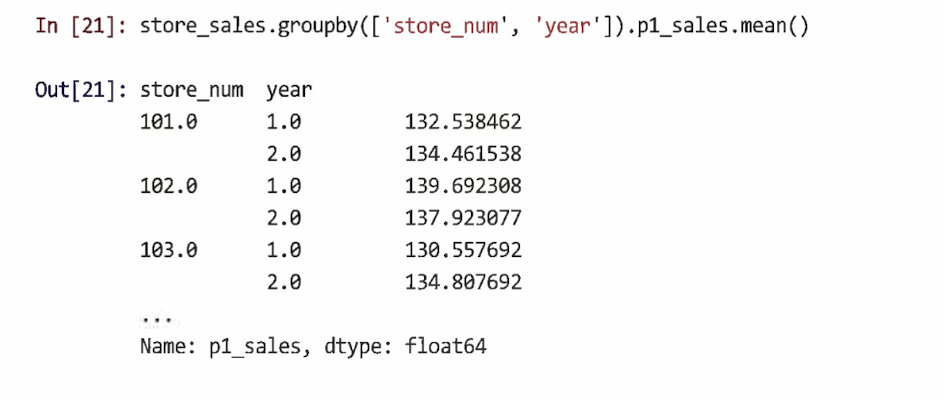
3.2.1 groupby()
3.2.2 이산변수
이산데이터를 설명하는 기본 방법은 빈도수, value_counts() 메서드 사용
3.2.3. 연속 변수
단위 판매 또는 가계 소득과 같은 일반적으로 발생하는 기울어진 비대칭 분포의 경우 mean(), std()보다는 median()및 사분위수 범위가 분포를 요약하는데 더 유용
- IQR 함수 정의

- 데이터 프레임 생성

판매에 대한 중앙값은 제품1이 2보다 더 높고 판매 변동(IQR)도 더 심하다는 것을 확인할 수 있음
3.3 데이터 프레임 요약
- describe()
- apply() : iqr()함수와 같이 사용자 정의 함수를 dataframe에 적용해주기 위해 사용
- 람다 함수 사용

3.4 단일 변수 시각화
3.4.1 히스토그램
plt.xticks()로 x축 숫자 설정 ,density()로 평활화 추정선 추가
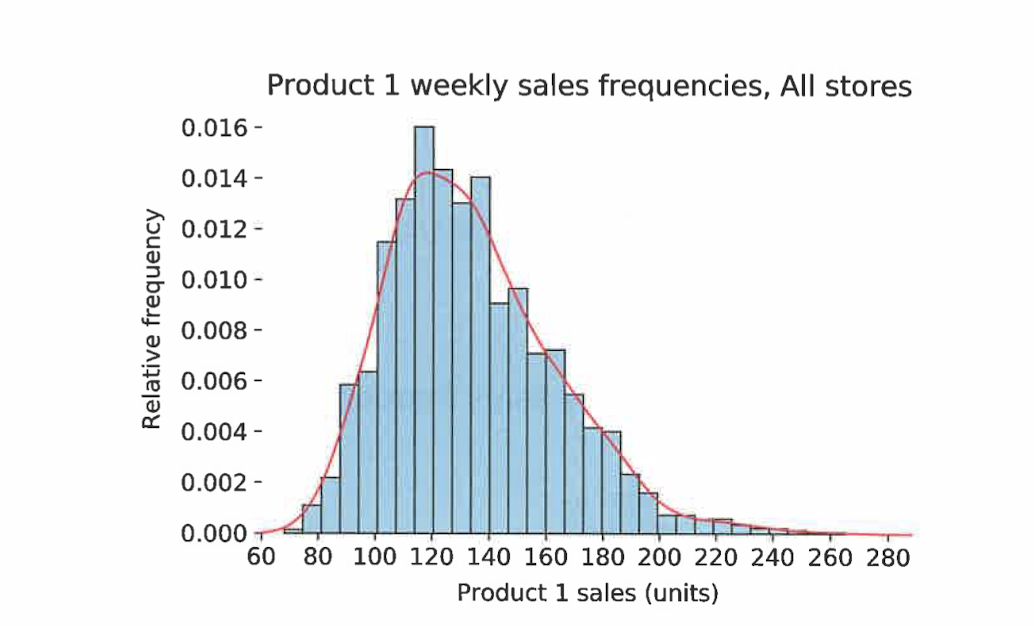
매주 제품 1의 판매량과 일반적인 판매량은 약 80에서 200사이라는 상황을 잘 설명해줌
3.4.2 상자그림
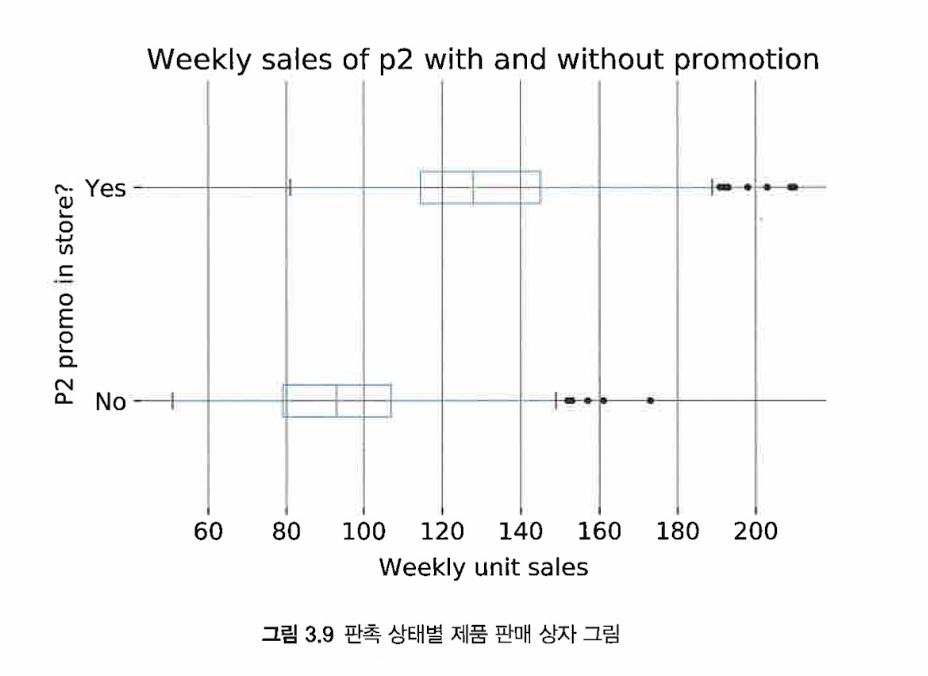
중앙값은 중심선 1분위, 3분위는 상자를 정의
바깥쪽 선은 상자의 너비의 1.5배 이하인 가장 극단적인 값 지점의 수염
수염을 벗어난 포인트는 특이값
상자그림은 분포를 시각화하고 결과변수가 다른 요인과 어떻게 관련돼 있는지 쉽게 탐색할 수 있게 함
3.4.3 정규성 확인을 위한 QQ도면
분위수-분위수 도면은 데이터의 모집단에 대해 추정한 분포가 맞는지 확인해보는데 좋음
분포가 실제로 정규분포인지 확인할 수 있음
- log 변환 후 p1_sales가 정규분포인지 scipy.stats.probplot()으로 조사


3.4.4 누적 분포
샘플에서 데이터 값의 누적 비율을 보여주는 단순한 도면
데이터의 불연속성, 긴꼬리, 특정 관심 지점과 같은 데이터 특징을 강조하는 좋은 방법
- ECDF()를 이용한 누적 분포도


3.4.5 지도
- cartopy 함수 사용

'데이터 > 마케팅' 카테고리의 다른 글
| [파이썬으로 하는 마케팅 연구와 분석] Chapter 5 | 그룹비교 테이블 및 시각화 (1) | 2023.03.29 |
|---|---|
| [파이썬으로 하는 마케팅 연구와 분석] Chapter 4 | 연속변수 간의 관계 (0) | 2023.03.29 |