
5.1 소비자 세그먼트 데이터 시뮬레이션
예제로 사용할 데이터셋은 구독 기반 서비스를 이용하는 N=300명의 응답자로부터 연령, 소득, 자녀 수, 주택 소유 or 임대 여부, 현재 제공되는 서비스 가입여부에 대한 데이터 수집
세그먼트의 생성은 휴리스틱(heuristic)에 의해 생성 가능
휴리스틱이란?
합리적인 사고방식을 기반으로 결론을 도출하는 것이 아닌, 경험에 기반하여 문제를 해결하는 방법 (ex) 어림법, 주먹구구법,발견법)
각 응답자를 'Suburb mix', 'Urban hip', 'Travelers', 'Moving up' 네 가지 소비자 세그먼트 중 하나에 할당
- 세그먼트를 위한 코드는 크게 세 부분으로 분리됨
- 데이터 구조 정의 : 인구 통계학적 변수(연령, 성별 등)와 세그먼트 이름 및 크기
- 인구 통계학적 변수(연령, 성별 등)의 분포에 대한 매개변수(평균, 분산 등)
- 세그먼트와 변수를 반복해 해당 정의와 매개변수에 따라 임의의 값을 추출하는 코드
- 데이터 적재(책 제공 웹사이트 이용)


5.1.1 세그먼트 데이터 정의
- 변수 이름과 분포 유형 정의
- normal: 정규(연속형), binomal: 이항(예/아니오), poisson : 포아송(개수)

이항분포란?
연속된 번 독립적 시행에서 각 시행이 확률 를 가질 때의 이산확률분포
특정 성공 확률()을 갖는 이벤트를 번 독립적으로 연속 수행하는 일이다. 성공 횟수 k, n-k는 실패 횟수가 됨
ex) 동전 던지기(앞/뒤) p는 0.5인 사건을 연속 n회 수행했을 때 0~n회 중 성공할 횟수인 모든 k에 대해 확률분포를 그릴 수 있음

포아송 분포란?
단위시간 동안 혹은 단위공간에서 어떤 사건이 발생하는 횟수를 나타내는 확률분포
푸아송 분포의 확률변수 는 단위시간 혹은 단위공간 내의 발생 횟수
λ는 해당 단위시간 혹은 단위공간 내에서 랜덤하게 발생하는 사건의 평균 횟수
ex ) 1시간 동안 은행에 방문하는 고객의 수, 1시간 동안 콜센터로 걸려오는 전화의 수

- 각 변수에 대한 통계 정의

해당 매개변수(평균, 분산 등)가 있는 분포에서 데이터를 샘플링하기 위해 이항, 포아송의 경우(gender, own_home, subscribe) 평균으로 분포가 지정되기 때문에 평균만 지정하면 된다.
정규 분포(age, income)의 경우 평균과 표준편차로 분포에 대한 모양이 결정 되기 때문에 분산에 대한 정보를 추가로 지정해야한다.
- 정규 분포인 age, income에 대한 표준편차 정의

- 세그먼트와 모든 칼럼에 대한 평균, 표준편차 정보를 포함한 딕셔너리 생성

5.1.2 최종 세그먼트 데이터 생성
세그먼트 데이터를 생성하기 위한 로직은 중첩 for 루프 사용하는 것
하나는 세그먼트용 다른 하나는 변수들의 집합용으로 사용
- dict에 데이터를 생성한 다음 분석을 위해 dataframe 변환
- 데이터 유형에 따라 적절한 유사 난수 함수 사용
- np.random.normal (loc, scale, size) : 정규분포로부터 임의의 난수들 만드는 함수(loc-평균의 위치, sclae - 표준편차, size-난수 개수)
- np.random.poisson(lam, size) : 일정한 단위 시간, 혹은 공간에서 무작위로 발생하는 사건의 평균 회수의 난수를 만드는 함수(lam =lambda, 발생 사건 평균 회수, size-난수 개수)
- np.random.binomial(n, p, size) : n 시행 횟수 동안 p 성공 확률을 가진 난수를 만드는 함수 (n -시행횟수, p-성공확률, size-난수 개수)
- 단일 명령으로 주어진 세그먼트 내의 size 대한 모든 값 추출
# 중첩 for loop를 통한 최종 세그먼트 데이터 생성
import numpy as np
np.random.seed(seed=2554)
segment_constructor = {}
#세그먼트를 반복하며 데이터 생성
for name in segment_names:
segment_data_subset={}
print('segment:{0}'.format(name))
#각 세그먼트 내에서 변수(feature)를 반복하며 데이터 생성
for variables in segment_variables:
print('\tvariable:{0}'.format(variables))
#정규형 변수에 적절한 유사 난수 함수로 데이터 추출
if segment_variables_distribution[variable] == 'normal':
segment_data_subset[variable] = np.random.normal(
loc = segment_statistics[name][variable]['mean'],
scale = segment_statistics[name][variable]['stddev'],
size = segment_statistics[name]['size']
)
#포아송 변수에 적절한 유사 난수 함수로 데이터 추출
elif segment_variables_distribution[variable] == 'poission':
segment_data_subset[variable] = np.random.poisson(
lam = segment_statistics[name][variable]['mean'],
size = segment_statistics[name]['size']
)
#이항 변수에 적절한 유사 난수 함수로 데이터 추출
elif segment_variables_distribution[variable] == 'binomial':
segment_data_subset[variable] = np.random.binomial(
n=1,
p = segment_statistics[name][variable]['mean'],
size = segment_statistics[name]['size']
)
#알 수 없는 데이터 형식
else:
print('Bad segment data type :{0}'.format(segment_variables_distribution[i]))
raise StopIteration
segment_data_subset['Segment'] = np.repeat(
name,
repeats = segment_statistics[name]['size']
)- suburb_mix 세그먼트의 age feature의 mean은 40, 표준편차는 5 , 해당 정규분포로부터의 10개의 난수 생성

5.2 그룹별 설명 찾기
소비자 세그먼트 데이터의 경우 가구 소득 및 성별과 같은 측정값이 세그먼트별로 어떻게 다른지에 관심이 있기 때문에 관심있는 세그먼트를 접근하는 방식에 대해 알아본다.
- 기준에 맞는 데이터프레임 인덱싱을 사용

- groupby()와 unstack() 메서드 사용
- unstack()메서드는 segment는 열, subscribe는 행으로 만듦

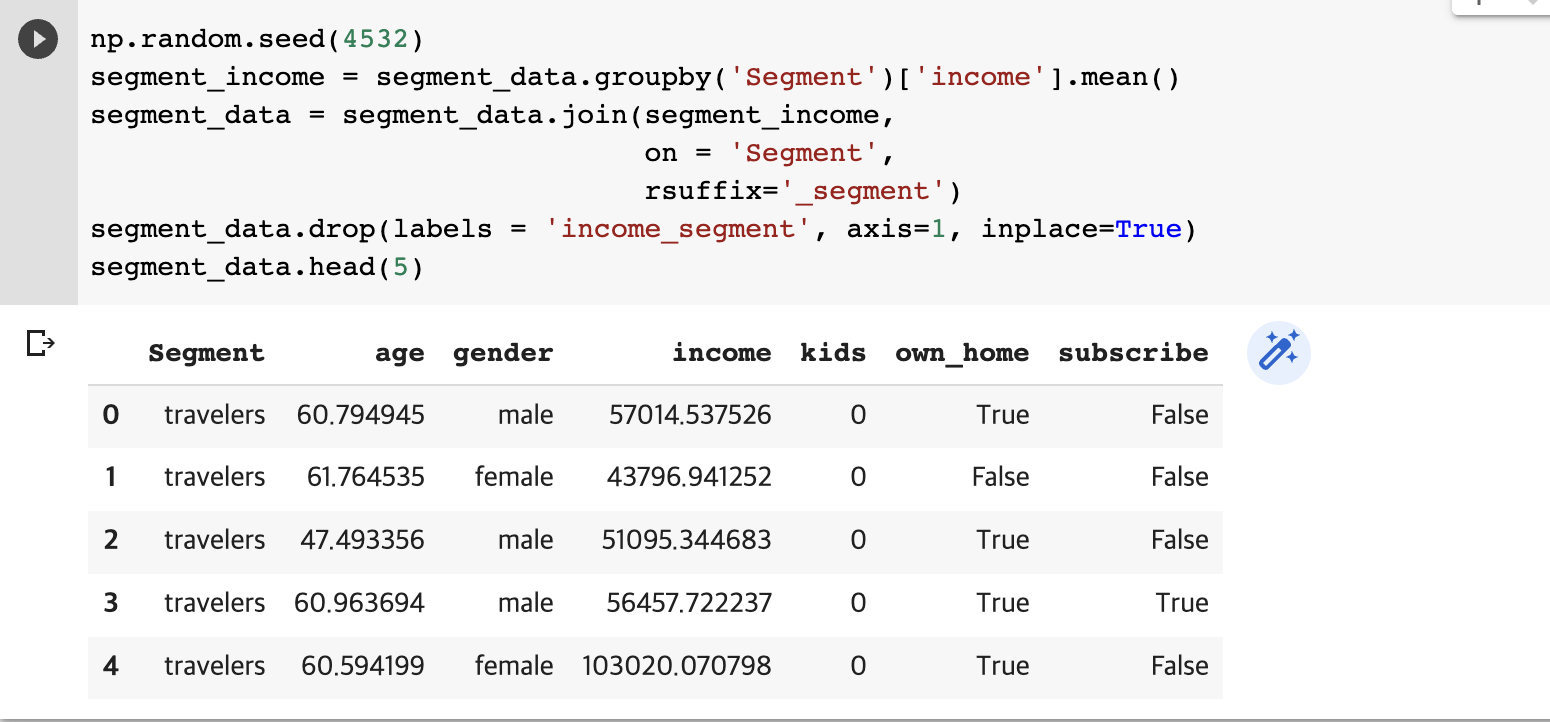
- 데이터셋에 세그먼트 평균열을 추가하기 위해 groupby(), join() 사용
- join()은 DataFrame과 공통되는 Series 결합
- 기존 데이터는 segment_income 필요 없기 때문에 drop() 메서드 사용, axis=1은 열 삭제, inplace는 개체 자체의 칼럼을 삭제
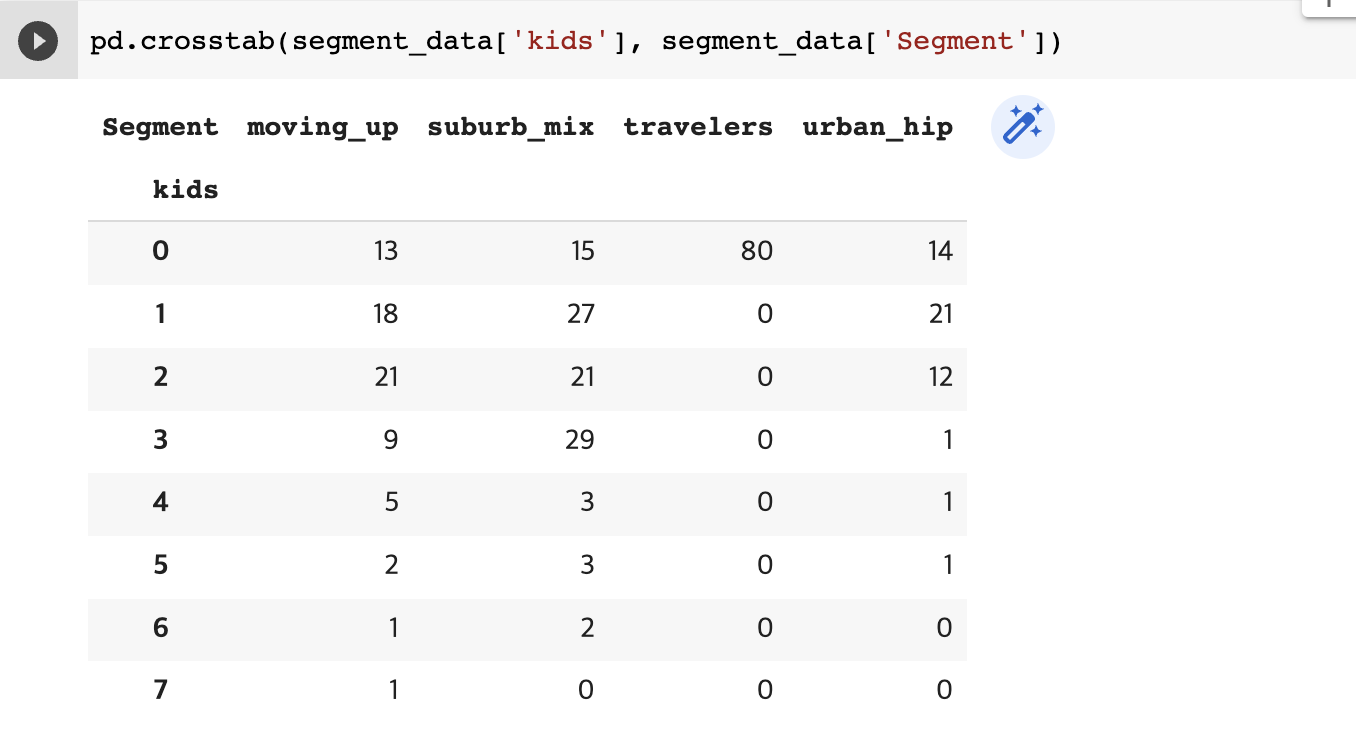
5.2.1 양방향 그룹에 대한 설명
- 각 교차점에 대한 발생횟수를 알려주는 crosstab()함수
5.2.2 그룹별 시각화 : 빈도와 비율
- matplotlib 패키지

- seaborn 패키지의 facetgrid()
- orient-플롯의 방향 (v:수직, h:수평), ci- 오차막대 파라미터
- 주택 소유 요인까지 고려해서 그래프 출력
g = sns.FacetGrid(segment_data, col = 'Segment', row= 'own_home')
g.map(sns.barplot, 'subscribe', orient='v', ci=None)
5.2.3 그룹별 시각화: 연속데이터
- seaborn 의 barplot()을 사용하여 세그먼트별 평균 수입 데이터 시각화(estimator=np.mean으로 각 등급별 평균 확인)
sns.barplot(x='Segment', y='income', data=segment_data, color='.6',
estimator=np.mean, ci=95)
- 상자그림 boxplot()
상자 그림은 값의 분포를 더 많이 보여주기 때문에 막대 차트보다 보기 좋음
- 세그먼트별 소득과 주택 비교를 위해 hue 파라미터 사용
sns.boxplot(x='Segment', y='income', hue = 'own_home',data=segment_data,
color = '0.7', orient='h')
세그먼트 내에서 소득과 주택 소유 간의 일관된 관계가 없는 것을 확인할 수 있음
'데이터 > 마케팅' 카테고리의 다른 글
| [파이썬으로 하는 마케팅 연구와 분석] Chapter 4 | 연속변수 간의 관계 (0) | 2023.03.29 |
|---|---|
| [파이썬으로 하는 마케팅 연구와 분석] Chapter 3 | 데이터 설명 (2) | 2023.03.29 |